
摘要
version:6.5.4 例子三台服务器ip为:192.168.23.177~179
# 一:概述
# 背景
常见的数据库都会提供备份的机制,以解决在数据库无法使用的情况下,可以开启新的实例,然后通过备份来恢复数据减少损失。虽然 Elasticsearch 有良好的容灾性,但由于以下原因,其依然需要备份机制。
- 数据灾备。在整个集群无法正常工作时,可以及时从备份中恢复数据。
- 归档数据。随着数据的积累,比如日志类的数据,集群的存储压力会越来越大,不管是内存还是磁盘都要承担数据增多带来的压力,此时我们往往会选择只保留最近一段时间的数据,比如1个月,而将1个月之前的数据删除。如果你不想删除这些数据,以备后续有查看的需求,那么你就可以将这些数据以备份的形式归档。
- 迁移数据。当你需要将数据从一个集群迁移到另一个集群时,也可以用备份的方式来实现。
Elasticsearch 做备份有两种方式,一是将数据导出成文本文件,比如通过 elasticdump (opens new window)、esm (opens new window) 等工具将存储在 Elasticsearch 中的数据导出到文件中。二是以备份 elasticsearch data 目录中文件的形式来做快照,也就是 Elasticsearch 中 snapshot 接口实现的功能。第一种方式相对简单,在数据量小的时候比较实用,当应对大数据量场景效率就大打折扣。下文重点使用第二种,即 snapshot api 的使用。
# 注册方式
Elasticsearch 支持多种仓库注册方式: 官方文档: https://www.elastic.co/guide/en/elasticsearch/reference/current/snapshot-restore.html https://www.elastic.co/guide/en/elasticsearch/reference/current/backup-cluster-data.html
- S3 repository support
- HDFS repository support in Hadoop environments
- Azure storage repositories
- Google Cloud Storage repositories
# 插件安装
如不使用HDFS略过此步骤
- 在线安装
./plugin install elasticsearch/elasticsearch-repository-hdfs/2.4.4- 离线安装 从插件镜像地址1 (opens new window) 或 插件镜像地址2 (opens new window)下载插件压缩包,然后执行
./plugin install file:///elasticsearch-repository-hdfs-2.4.4-hadoop2.zip
# 二:创建快照
ElasticSearch提供了snapshot功能,首先需要编辑 config/elasticsearch.yml 文件增加备份库存的位置。比如 path.repo: ["/home/backup/es","/mount/backups"],需要在集群所有存储节点中进行配置
# 创建repo
# 使用file system注册
使用共享文件系统
[root@ccj ~]# curl -XPUT 'http://localhost:9200/_snapshot/my_repository' -d '
{
"type": "fs",
"settings": {
"location": "/home/backup/es/my_repository",
"compress": true
}
}'
2
3
4
5
6
7
8
初始化完成之后就可以在这个repository中来备份数据了
# 使用hdfs注册
uri指定了Hadoop的NameNode地址
[root@ccj ~]# curl -XPUT 'http://localhost:9200/_snapshot/my_repository' -d '
{
"type": "fs",
"settings": {
"location": "/home/backup/es/my_repository",
"compress": true
}
}'
2
3
4
5
6
7
8
# 创建snapshot
# 全局索引
有了 repostiroy 后,我们就可以做备份了,也叫快照,也就是记录当下数据的状态。 Elasticsearch创建数据快照是以index为单位进行的,可以使用缺省模式默认创建所有index的副本,也可以进行指定。 对所有index一个名为snapshot_1的snapshot:
[root@ccj ~]# curl -XPUT 'http://localhost:9200/_snapshot/backup/snapshot_1?wait_for_completion=true'
返回结果的参数意义都是比较直观的,比如 indices 指明此次备份涉及到的索引名称,由于我们没有指定需要备份的索引,这里备份了所有索引;state 指明状态;duration_in_millis 指明备份任务执行时长等。
# 指定索引
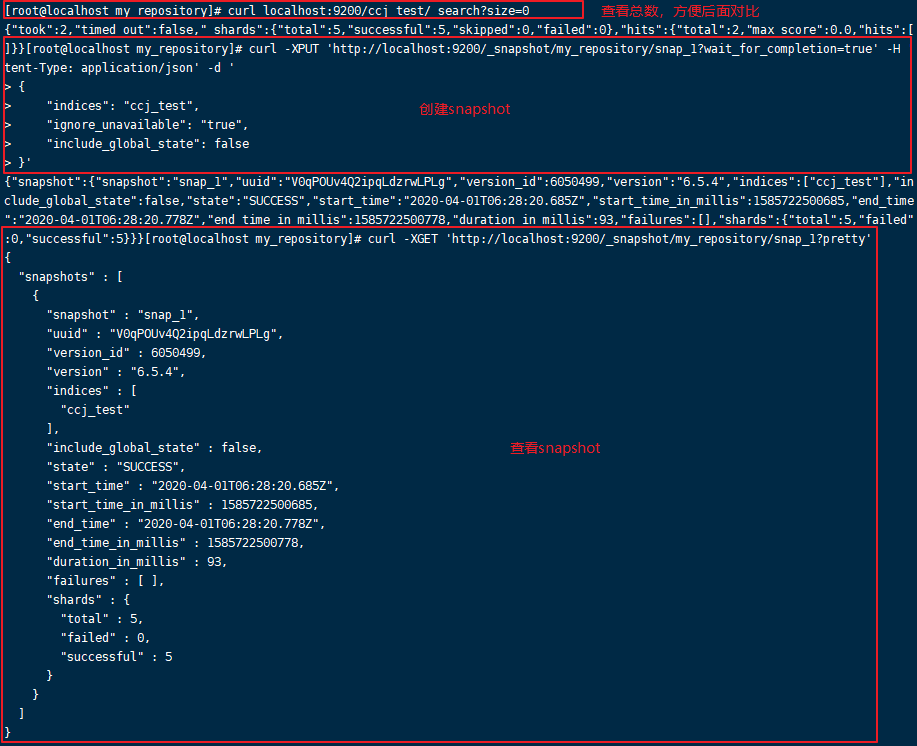
指定index(ccj_test)创建snapshot:
[root@ccj ~]# curl -XPUT 'http://localhost:9200/_snapshot/my_repository/snap_1?wait_for_completion=true' -H 'Content-Type: application/json' -d '
{
"indices": "ccj_test",
"ignore_unavailable": "true",
"include_global_state": false
}'
2
3
4
5
6
快照创建时不会影响搜索查询,并且快照创建过程启动后,新的数据不会被记录到快照中,同一时刻只能有一份快照被创建。 wait_for_completion 为 true 是指该 api 在备份执行完毕后再返回结果,否则默认是异步执行的,这里为了立刻看到效果,所以设置了该参数,线上执行时不用设置该参数,让其在后台异步执行即可。也可用下面的命令查看。
# 查看快照进度
[root@ccj ~]# curl -XGET "http://localhost:9200/_snapshot/my_repository/snap_1/_status?pretty"
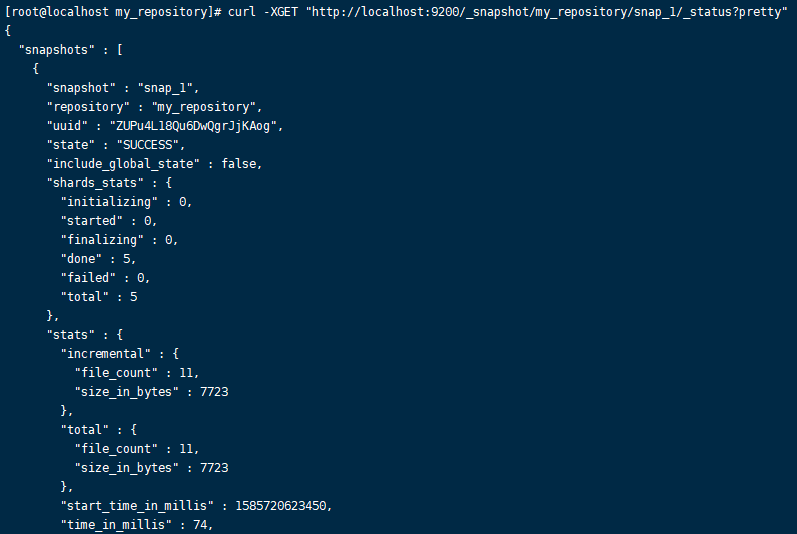
# 查看snapshot
[root@ccj ~]# curl -XGET 'http://localhost:9200/_snapshot/my_repository/snap_1?pretty'
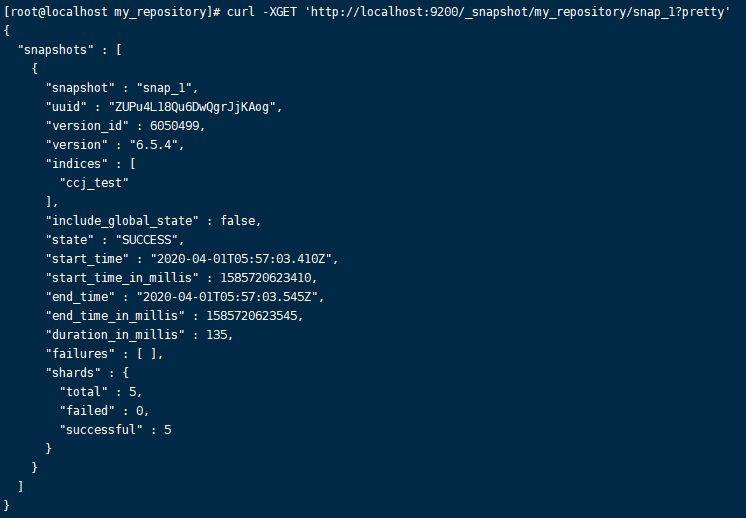
# 查看所有snapshot
[root@ccj ~]# curl -XGET 'http://localhost:9200/_snapshot/my_repository/snap_1?pretty'
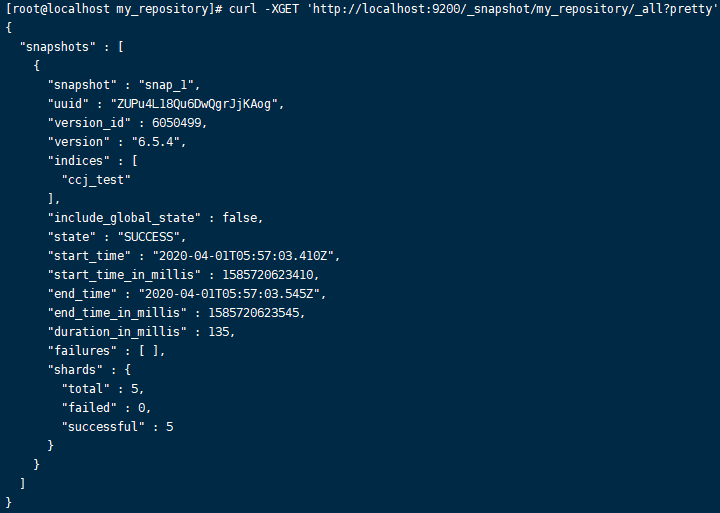
# 三:增量备份
通过上面的步骤我们成功创建了一个备份,但随着数据的新增,我们需要对新增的数据也做备份,那么我们如何做呢?方法很简单,只要再创建一个快照 snapshot_2 就可以了。
PUT /_snapshot/my_backup/snapshot_2?wait_for_completion=true
当执行完毕后,你会发现 /mount/backups/my_backup 体积变大了。这说明新数据备份进来了。要说明的一点是,当你在同一个 repository 中做多次 snapshot 时,elasticsearch 会检查要备份的数据 segment 文件是否有变化,如果没有变化则不处理,否则只会把发生变化的 segment file 备份下来。这其实就实现了增量备份。
elasticsearch 的资深用户应该了解 force merge 功能,即可以强行将一个索引的 segment file 合并成指定数目,这里要注意的是如果你主动调用 force merge api,那么 snapshot 功能的增量备份功能就失效了,因为 api 调用完毕后,数据目录中的所有 segment file 都发生变化了。
另一个就是备份时机的问题,虽然 snapshot 不会占用太多的 cpu、磁盘和网络资源,但还是建议大家尽量在闲时做备份。
# 四:删除快照
删除操作可以终止一个正在进行的快照备份
# 删除快照
[root@ccj ~]# curl -XGET 'http://localhost:9200/_snapshot/my_repository/snap_1?pretty'

# 五:恢复快照
在两个不同的ES集群中迁移恢复数据时,我们需要保证一些条件。
- 新集群版本应该比创建snapshot的集群版本更高
- 新集群应该有足够的空间存储快照中的所有index,当然也可以指定部分index恢复以适应小集群
- 如果旧集群中有index的shard分配到指定的节点上,那么新集群恢复时也会遵循此规则,因此如果新集群不包含指定节点时,这一部分index将无法恢复
# 恢复snapshot
[root@ccj ~]# curl -XPOST 'http://localhost:9200/_snapshot/my_repository/snap_1/_restore?wait_for_completion=true&pretty' -H 'Content-Type: application/json' -d '
{
"indices": "ccj_test",
"ignore_unavailable": "true",
"include_global_state": false,
"rename_pattern": "ccj_test",
"rename_replacement": "restore_ccj_test"
}'
2
3
4
5
6
7
8
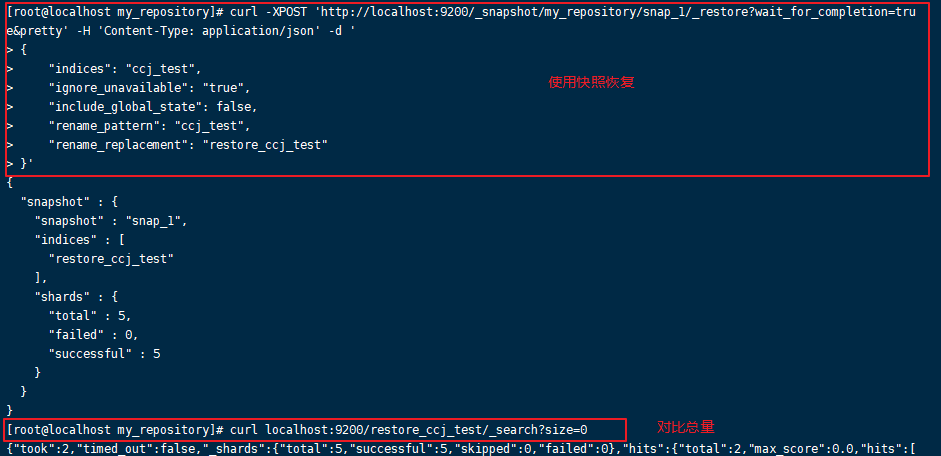
参数 rename_pattern 和 rename_replacement 用来正则匹配要恢复的索引,并且重命名。下面的例子:test-index => copy_index, test_2 => coyp_2
[root@ccj ~]# curl -XPOST "http://localhost:9200/_snapshot/my_repository/snap_1/_restore?wait_for_completion=true&pretty" -H 'Content-Type: application/json' -d '
{
"indices": "test-index,test-2",
"ignore_unavailable": "true",
"include_global_state": false,
"rename_pattern": "test-(.+)",
"rename_replacement": "copy_$1"
}'
2
3
4
5
6
7
8
# 六:HDFS
# 待续
- ElasticSearch Guide (opens new window)
- Elasticsearch备份数据到HDFS (opens new window)
- ElasticSearch的备份迁移方案 (opens new window)
# 七:报错解决
# 错误
# 解决方法
elasticsearch账号没有改目录权限,分配相关权限
[root@ccj ~]# sudo chown -R elasticsearch:elasticsearch /home/backup/
# 八:参考链接
# 九:待续未看
- Elasticsearch数据备份说明 (opens new window)
- Elasticsearch 备份并在另一个集群恢复 (opens new window)
- Elasticsearch数据备份与恢复 (opens new window)
- Elasticsearch索引迁移的四种方式 (opens new window)
- Elasticsearch跨集群数据迁移之离线迁移 (opens new window)
- Elasticsearch数据迁移工具elasticdump工具 (opens new window)
- 如何迁移至 Kibana Spaces (opens new window)
- 过elasticsearch-migration工具做新老集群数据迁移 (opens new window)
- elasticsearch数据迁移 (opens new window)