
# 一:基本命令
- 命令输入在
mysql>之后 - 命令用
;或\g结束,换句话说,仅按Enter不执行命令 - 输入
help或\h获取帮助,也可以输入跟多的文本获取特定命令的帮助(如,输入help select获得使用 SELECT 语句的帮助) - 输入
quit或exit退出命令行实用程序
# 1.1 连接客户端
- -h:主机名,表示要连接的数据库的主机名或者IP,默认127.0.0.1
- -P:端口,表示要连接的数据库的端口,默认是3306
- -u:用户名,表示连接数据库的用户名
- -p:密码,-p后面可以直接输入密码,但是这样密码就会明文输入不太安全,所以建议输入-p回车,换行输入密码
mysql -u root -p
# 1.2 选择数据库
- 必须先使用
USE指定数据库,才能读取其中的数据 - 数据库名区分大小写
USE mysql;

# 1.3 SHOW
| 命令 | 说明 |
|---|---|
| SHOW DATABASES | 查看可用的数据库 |
| SHOW TABLES | 查看某数据库下可用的表 |
| SHOW COLUMNS FROM 表名 可用DESCRIBE 表名 替代 | 查看表的列 |
| SHOW STATUS | 展示服务器状态信息 |
| SHOW CREATE DATABASE 数据库名 | 展示数据库创建语句 |
| SHOW CREATE TABLE 表名 | 展示表创建语句 |
| SHOW GRANTS [FOR username] | 展示所有/特定用户的安全权限 |
| SHOW ERRORS | 展示服务器错误信息 |
| SHOW WARNINGS | 展示服务器警告信息 |
| SELECT version() | 查看Mysql版本 |
更多SHOW命令可查看 官方文档 (opens new window)
或 【HELP SHOW】
运行结果
> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| ccj_test |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
-- 上面除了ccj_test 都是系统库
-- 下面查看ccj_test库下可用的表
> SHOW TABLES;
+--------------------+
| Tables_in_ccj_test |
+--------------------+
| customers |
| orderitems |
| orders |
| productnotes |
| products |
| vendors |
+--------------------+
6 rows in set (0.00 sec)
-- 下面查看customers表的显示列
> SHOW COLUMNS FROM customers;
+--------------+-----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------+------+-----+---------+----------------+
| cust_id | int(11) | NO | PRI | NULL | auto_increment |
| cust_name | char(50) | NO | | NULL | |
| cust_address | char(50) | YES | | NULL | |
| cust_city | char(50) | YES | | NULL | |
| cust_state | char(5) | YES | | NULL | |
| cust_zip | char(10) | YES | | NULL | |
| cust_country | char(50) | YES | | NULL | |
| cust_contact | char(50) | YES | | NULL | |
| cust_email | char(255) | YES | | NULL | |
+--------------+-----------+------+-----+---------+----------------+
9 rows in set (0.00 sec)
-- SHOW COLUMNS FROM 可以用 DESCRIBE
> SHOW STATUS;
内容略
> SHOW CREATE DATABASE ccj_test;
+----------+----------------------------------------------------------------------+
| Database | Create Database |
+----------+----------------------------------------------------------------------+
| ccj_test | CREATE DATABASE `ccj_test` /*!40100 DEFAULT CHARACTER SET utf8mb4 */ |
+----------+----------------------------------------------------------------------+
1 row in set (0.00 sec)
> SHOW CREATE TABLE customers;
+-----------+-------------------------------------------------------------------+
| Table | Create Table |
+-----------+-------------------------------------------------------------------+
| customers | CREATE TABLE `customers` (
`cust_id` int(11) NOT NULL AUTO_INCREMENT,
`cust_name` char(50) NOT NULL,
`cust_address` char(50) DEFAULT NULL,
`cust_city` char(50) DEFAULT NULL,
`cust_state` char(5) DEFAULT NULL,
`cust_zip` char(10) DEFAULT NULL,
`cust_country` char(50) DEFAULT NULL,
`cust_contact` char(50) DEFAULT NULL,
`cust_email` char(255) DEFAULT NULL,
PRIMARY KEY (`cust_id`)
) ENGINE=InnoDB AUTO_INCREMENT=10006 DEFAULT CHARSET=utf8mb4 |
+-----------+-------------------------------------------------------------------+
1 row in set (0.00 sec)
-- 全部
> SHOW GRANTS;
+---------------------------------------------------------------------+
| Grants for root@localhost |
+---------------------------------------------------------------------+
| GRANT ALL PRIVILEGES ON *.* TO 'root'@'localhost' WITH GRANT OPTION |
| GRANT PROXY ON ''@'' TO 'root'@'localhost' WITH GRANT OPTION |
+---------------------------------------------------------------------+
2 rows in set (0.00 sec)
-- 特定
> SHOW GRANTS for root;
+-------------------------------------------------------------+
| Grants for root@% |
+-------------------------------------------------------------+
| GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION |
+-------------------------------------------------------------+
1 row in set (0.00 sec)
> SHOW GRANTS for root@localhost;
+---------------------------------------------------------------------+
| Grants for root@localhost |
+---------------------------------------------------------------------+
| GRANT ALL PRIVILEGES ON *.* TO 'root'@'localhost' WITH GRANT OPTION |
| GRANT PROXY ON ''@'' TO 'root'@'localhost' WITH GRANT OPTION |
+---------------------------------------------------------------------+
2 rows in set (0.00 sec)
> SHOW ERRORS;
Empty set (0.00 sec)
> SHOW WARNINGS;
Empty set (0.00 sec)
> SELECT version();
+-----------+
| version() |
+-----------+
| 5.7.36 |
+-----------+
1 row in set (0.00 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
# 二:DDL
# 2.1 创建表
- MySQL 语句中忽略空格。语句可以一行输入,也可以分成多行。作用都相同;
- NULL 为无值或缺值,允许该列插入时不给出该列的值。NULL为默认设置,可以不显式指定;
- NULL值非空串,NULL值用关键字NULL指定,而非 ''
- MySQL的默认值只支持常量,不支持使用函数,例如:
quantity int NOT NULL DEFAULT 1 - 每个表只允许一个AUTO_INCREMENT列,而且它必须被索引;
-- 创建和更新时间自动赋值
created_time datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间'
updated_time datetime ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间'
-- 自增长
CREATE TABLE temp_customers (
cust_id int NOT NULL AUTO_INCREMENT,
cust_name char(50) NOT NULL,
cust_address char(50) NULL,
PRIMARY KEY (cust_id)
) ENGINE=InnoDB;
2
3
4
5
6
7
8
9
10
11
如果需要使用多个列,则这些列的组合值必须唯一。如:PRIMARY KEY (order_num, order_item)
处理现有的表
创建新表时,指定的表名必须不存在,否则将出错。如果要防止意外覆盖已有的表,SQL要求首先手工删除该表,然后再重建它,而不是简单用创建表语句覆盖它。如果仅想在一个表不存在时创建它,应该在表名后给出 IF NOT EXISTS,这样做不检查已有表的模式是否与打算创建的表模式相匹配。只查看表名是否存在。
CREATE TABLE IF NOT EXISTS temp_customers (
cust_id int NOT NULL AUTO_INCREMENT,
cust_name char(50) NOT NULL,
cust_address char(50) NULL,
PRIMARY KEY (cust_id)
) ENGINE=InnoDB;
2
3
4
5
6
数据类型:
数据类型
字符串数据类型
| 数据类型 | 说明 |
|---|---|
| CHAR | 1~255个字符的定长串。它的长度必须在创建时指定,否则MySQL假定为CHAR(1) |
| ENUM | 接受最多 64K 个串组成的一个预定义集合的某个串 |
| LONGTEXT | 与TEXT相同,但最大长度为 4GB |
| MEDIUMTEXT | 与TEXT相同,但最大长度为 16K |
| SET | 接受最多64个串组成的一个预定义集合的零个或多个串 |
| TEXT | 最大长度为64K的变长文本 |
| TINYTEXT | 与TEXT相同,但最大长度为255字节 |
| VARCHAR | 长度可变,最多不超过255字节。如果在创建时指定为VARCHAR(n),则可存储0到n个字符的变长串(其中n≤255) |
不管使用何种形式的串数据类型,串值都必须括在引号内(通常单引号更好)
数值类型
所有数值数据类型(除 BIT 和 BOOLEAN 外)都可以是有符号或无符号。有符号数值列可以存储正或负的数值,无符号数值列只能存储正数。默认情况为有符号,但如果你知道自己不需要存储负值,可以使用 UNSIGNED 关键字,这样做将允许你存储两倍大小的值。
| 数据类型 | 说明 |
|---|---|
| BIT | 位字段,1~64位(在MySQL 5之前,BIT在功能上等价于TINYINT |
| BIGINT | 整数值,支持 -9223372036854775808~9223372036854775807(如果是UNSIGNED,为0~18446744073709551615)的数 |
| BOOLEAN(或BOOL) | 布尔标志,0或1,主要用于真/假标志 |
| DECIMAL(或DEC) | 精度可变的浮点值 |
| DOUBLE | 双精度浮点值 |
| FLOAT | 单精度浮点值 |
| INT(或INTEGER) | 整数值,支持 -2147483648~2147483647(如果是UNSIGNED,为0~4294967295)的数 |
| MEDIUMINT | 整数值,支持-8388608~8388607(如果是UNSIGNED,为0~16777215)的数 |
| REAL | 4字节的浮点值 |
| SMALLINT | 整数值,支持-32768~32767(如果是UNSIGNED,为0~65535)的数 |
| TINYINT | 整数值,支持-128~127(如果为UNSIGNED,为0~255)的数 |
与字符串不一样,数值不应该括在引号内。
MySQL中没有专门存储货币的数据类型,一般情况下使用DECIMAL(8, 2)。
时间日期类型
| 数据类型 | 说明 |
|---|---|
| DATE | 表示1000-01-01~9999-12-31的日期,格式为YYYY-MM-DD |
| DATETIME | DATE和TIME的组合 |
| TIMESTAMP | 功能和DATETIME相同(但范围较小),1970-01-01~2038-01-19的日期 |
| TIME | 格式为HH:MM:SS |
| YEAR | 用2位数字表示,范围是70(1970年)~69(2069年),用4位数字表示,范围是1901年~2155年 |
二进制类型
| 数据类型 | 说明 |
|---|---|
| BLOB | Blob最大长度为64 KB |
| MEDIUMBLOB | Blob最大长度为16 MB |
| LONGBLOB | Blob最大长度为4 GB |
| TINYBLOB | Blob最大长度为255字节 |
# 2.2 更新表
添加列
ALTER TABLE vendors ADD vend_phone CHAR(20);
常用于添加索引
ALTER TABLE vendors ADD INDEX index_vend_phone (vend_phone);
添加主键
ALTER TABLE cc ADD new_id INT(5) UNSIGNED NOT NULL AUTO_INCREMENT
,ADD PRIMARY KEY (new_id);
2
更新列
扩展长度或修改类型
ALTER TABLE vendors MODIFY vend_phone CHAR(70);
更改名字和类型
-- 下面语句没法用modify替代
ALTER TABLE vendors CHANGE vend_phone new_vend_phone VARCHAR(40);
2
修改ID为自增长,并设置主键
ALTER TABLE dd MODIFY id INT(5) AUTO_INCREMENT PRIMARY KEY;
删除列
ALTER TABLE vendors DROP vend_phone;
调整顺序
-- 新增字段在id之后
ALTER TABLE cc ADD address VARCHAR(50) AFTER id;
-- 调整自身顺序
ALTER TABLE cc MODIFY address VARCHAR(50) AFTER name;
-- 等同上面
ALTER TABLE cc CHANGE address address VARCHAR(50) AFTER name;
2
3
4
5
6
修改表名
ALTER TABLE vendors RENAME TO cc;
也可使用 RENAME TABLE 语句来重命名一个表
-- 修改单个
RENAME TABLE customers2 TO customers3;
-- 修改多个
RENAME TABLE customers2 TO customers3,
backup_vendors TO vendors2;
2
3
4
5
6
修改复杂的表结构一般需要手动删除过程,它涉及以下步骤:
用新的列布局创建一个新表;
使用INSERT SELECT语句,从旧表复制数据到新表。如果有必要,可使用转换函数和计算字段;
检验包含所需数据的新表;
重命名旧表(如果确定,可以删除它);
用旧表原来的名字重命名新表;
根据需要,重新创建触发器、存储过程、索引和外键。
同样,如果一张表数据量级是千万级别以上的,给这张表添加索引,可以参照上面步骤。
# 2.3 删除表
DROP TABLE customers;
同时也可以使用 IF EXISTS
DROP TABLE IF EXISTS customers;
# 2.4 新增索引
添加主键索引(PRIMARY KEY)
ALTER TABLE dd ADD PRIMARY KEY (id);
添加唯一索引(UNIQUE KEY)
ALTER TABLE dd ADD UNIQUE KEY (name);
添加普通索引(INDEX)
ALTER TABLE dd ADD INDEX index_address (address);
添加FULLTEXT(全文索引)
ALTER TABLE dd ADD FULLTEXT (new_address);
添加多列索引
ALTER TABLE dd ADD INDEX many_column (column1, column2, column3);
# 2.5 删除索引
首先查看表的索引
SHOW INDEX FROM dd;

删除索引
ALTER TABLE dd DROP INDEX new_address;
ALTER TABLE dd DROP INDEX many_column;
2
# 三:DML-SELECT
- 关键字不区分大小写,Select和SELECT一样。为了代码易于阅读和调试,关键字大写,列和表名使用小写。
- 为了易于阅读和调试,建议将SQL语句分为多行。
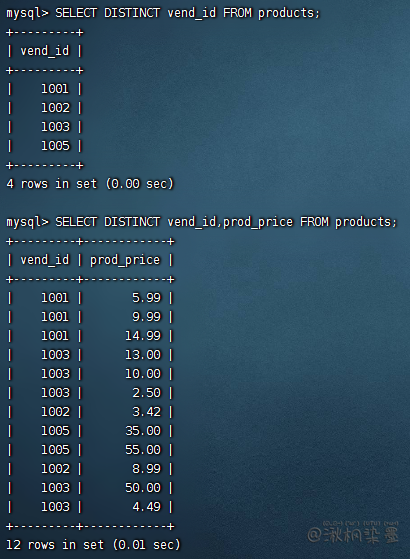
# 3.1 DISTINCT
去重
不能部分使用DISTINCT,除非指定的两个列都不同,否则所有行都将会被检索出来
# 3.2 条数
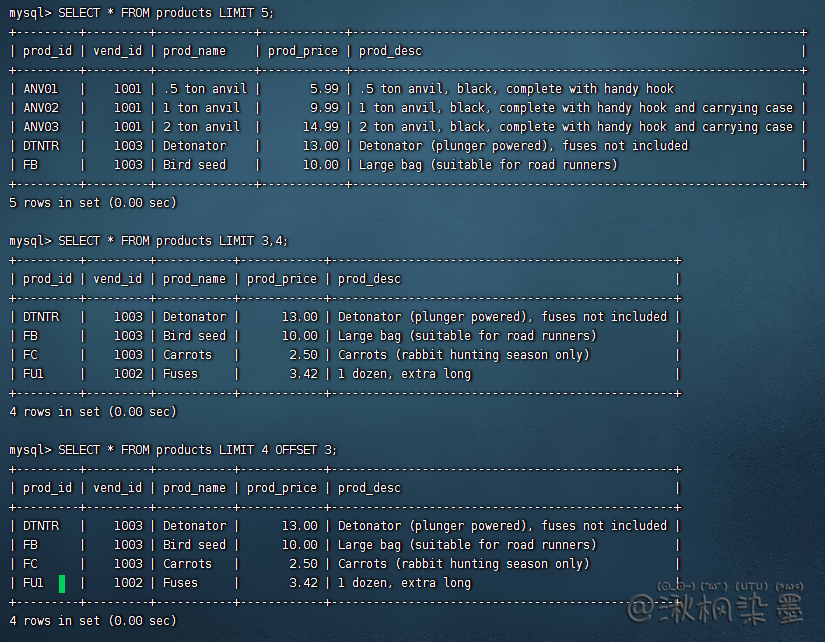
行数开始为0,非1
前5行
SELECT * FROM products LIMIT 5;
4~7行,第一个3为开始位置,第二个4为检索行数
SELECT * FROM products LIMIT 3,4;
因为容易混淆,所以MySQL5开始支持OFFSET 下面语句等同上面
SELECT * FROM products LIMIT 4 OFFSET 3;
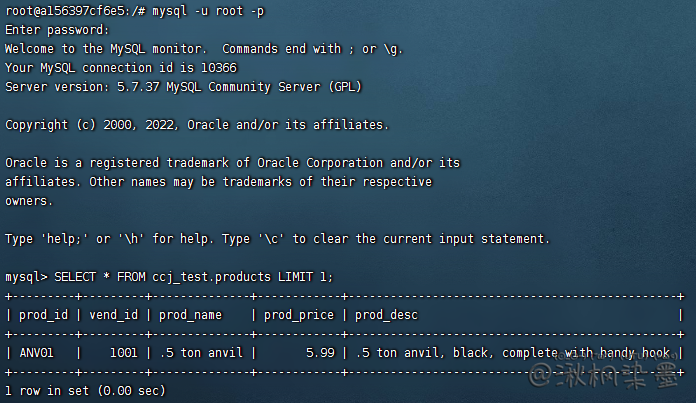
# 3.3 全限定
在未USE 数据库的情况下,通过库名等限定,直接执行语句,例如,下面访问 ccj_test 数据库下的 products。也可用于在USE 数据库下,访问其他未USE 但是有权限访问的其他数据库。
SELECT * FROM ccj_test.products LIMIT 1;
# 3.4 ORDER BY
排序
- ASC(ASCENDING)升序,默认
- DESC 降序
默认A和a顺序一致,在B之前,也可以通过配置修改规则
LIMIT 在 ORDER BY 之后
配合LIMIT
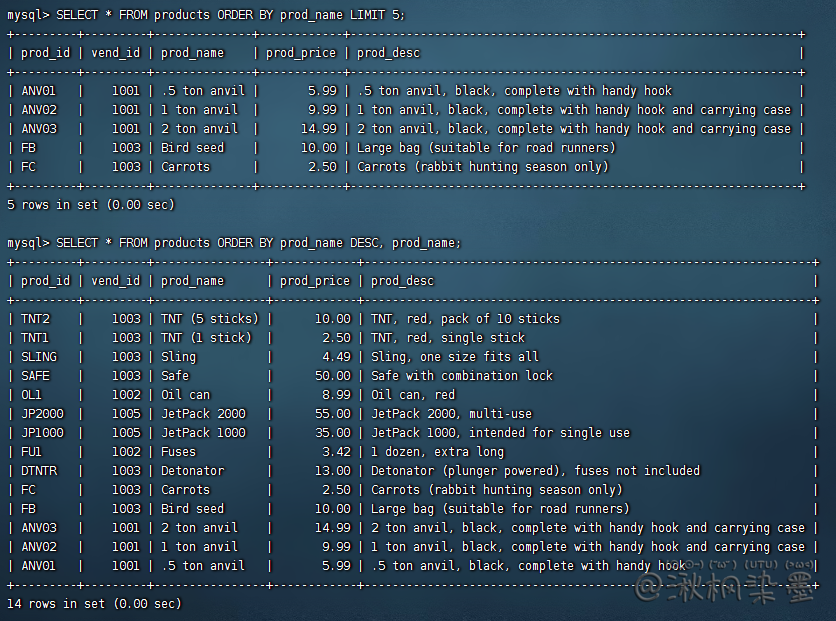
SELECT * FROM products ORDER BY prod_name LIMIT 5;
多个排序
SELECT * FROM products ORDER BY prod_name DESC, prod_name;
# 3.5 WHERE
| 操作符 | 说明 |
|---|---|
| = | 等于 |
| <> != | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| BETWEEN ... AND ... | 在指定的两个值之间(边界包含) |
排序在WHERE之后
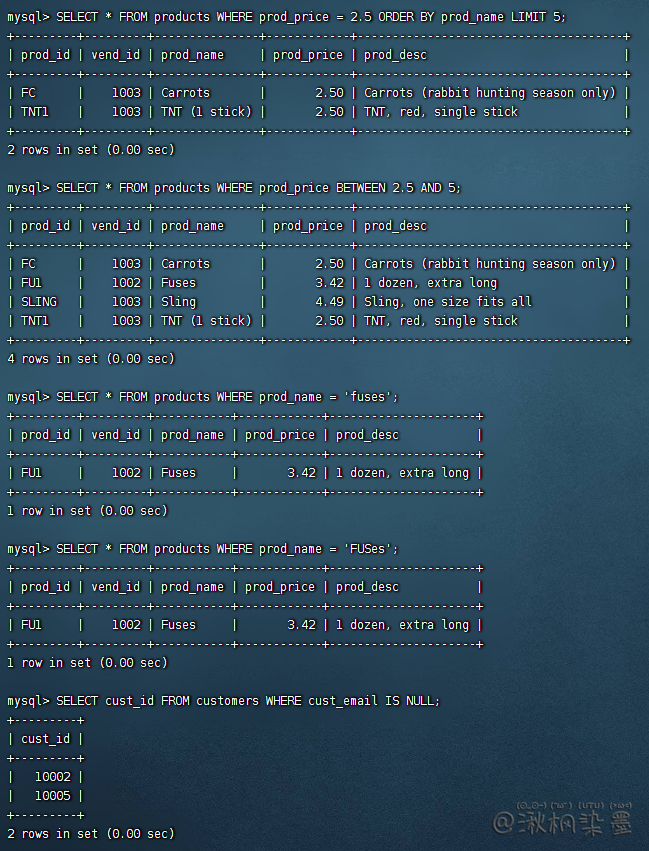
SELECT * FROM products WHERE prod_price = 2.5 ORDER BY prod_name LIMIT 5;
BETWEEN
SELECT * FROM products WHERE prod_price BETWEEN 2.5 AND 5;
下面两句效果等同,不区分大小写
SELECT * FROM products WHERE prod_name = 'fuses';
SELECT * FROM products WHERE prod_name = 'FUSes';
2
空值NULL
SELECT cust_id FROM customers WHERE cust_email IS NULL;
# 3.6 或且
- OR:或
- AND:和
问题SQL语句
SELECT * FROM products WHERE vend_id = 1003 OR vend_id = 1002 AND prod_price >= 10;
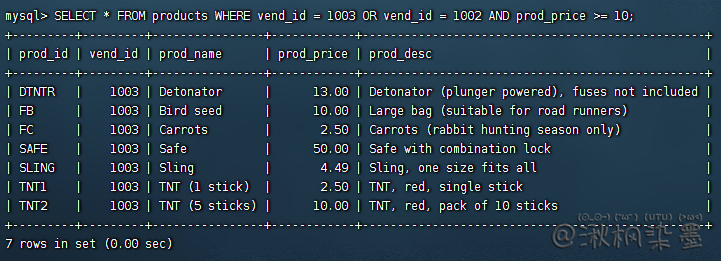
问题原因:次序,SQL在处理OR操作符前,优先处理AND操作符。当SQL看到上述语句理解为:
由供应商1002制造且价格为10美元(含)以上产品,或由供应商1003制造的产品,换句话说AND在计算机次序中优先级最高,操作符被错误地组合了
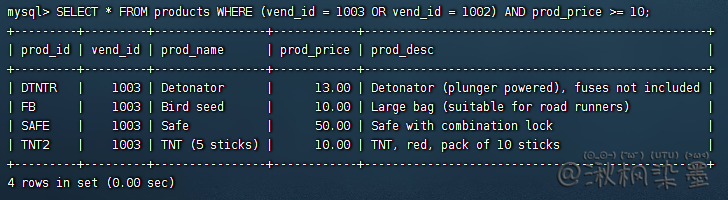
解决方法:添加括号,括号具有较AND或OR操作更高的计算次序。不要过分依赖默认计算次序
SELECT * FROM products WHERE (vend_id = 1003 OR vend_id = 1002) AND prod_price >= 10;
运算符优先级
| 优先级低到高 | 运 算 符 |
|---|---|
| 1 | =(赋值运算)、:= |
| 2 | |
| 3 | XOR |
| 4 | &&、AND |
| 5 | NOT |
| 6 | BETWEEN、CASE、WHEN、THEN、ELSE |
| 7 | =(比较运算)、<=>、>=、>、<=、<、<>、!=、 IS、LIKE、REGEXP、IN |
| 8 | | |
| 9 | & |
| 10 | <<、>> |
| 11 | -(减号)、+ |
| 12 | *、/、% |
| 13 | ^ |
| 14 | -(负号)、〜(位反转) |
| 15 | ! |
通过上面可以看出 NOT > AND > OR
# 3.7 IN
指定条件范围,范围中的每个条件都可以进行匹配。IN取合法值的由逗号分隔的清单,全都括在圆括号中。
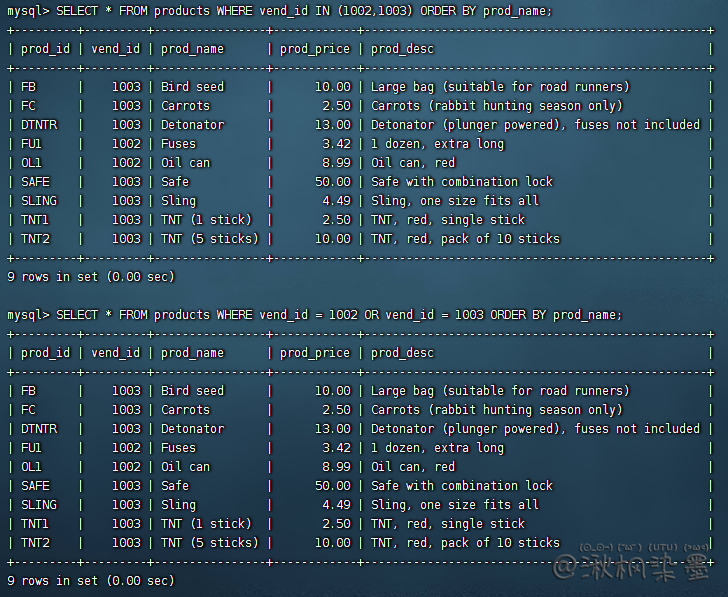
SELECT * FROM products WHERE vend_id IN (1002, 1003) ORDER BY prod_name;
等同下面
SELECT * FROM products WHERE vend_id = 1002 OR vend_id = 1003 ORDER BY prod_name;
优势:
- IN语法更清楚且直观
- IN操作符一般比OR操作符清单执行更快
- IN最大优点可以包含其他SELECT语句,使得能够更动态地建立WHERE子句
# 3.8 NOT
否定之后所跟的任何条件
支持对 IN、BETWEEN 和 EXISTS 子句取反
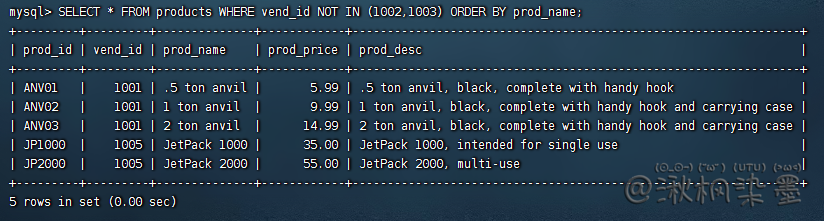
SELECT * FROM products WHERE vend_id NOT IN (1002,1003) ORDER BY prod_name;
# 3.9 LIKE
根据通配符匹配搜索
| 通配符 | 范围 |
|---|---|
| % | 0个以上字符,NULL值除外 |
| _ | 单个字符 |
不要过度使用通配符,如果其他操作符能达到相同目的,应该使用其他操作符;
尽可能不要把通配符放在搜索模式的开始处。这样搜索起来是最慢的。
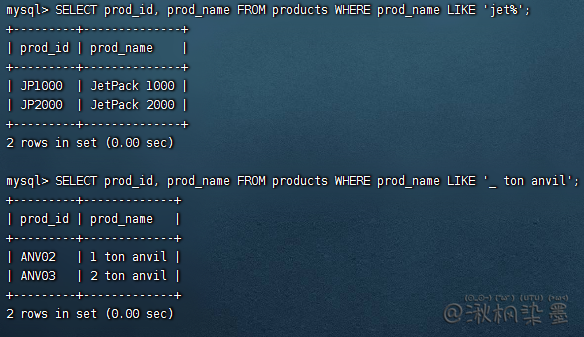
SELECT prod_id, prod_name FROM products WHERE prod_name LIKE 'jet%';
SELECT prod_id, prod_name FROM products WHERE prod_name LIKE '_ ton anvil';
2
# 3.10 正则
对比下面两个SQL,以及结果:
SELECT prod_name FROM products WHERE prod_name REGEXP '1000' ORDER BY prod_name;
SELECT prod_name FROM products WHERE prod_name LIKE '1000' ORDER BY prod_name;
2
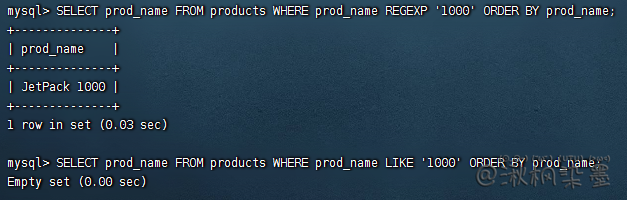
LIKE匹配整个列,不使用通配符情况下,等同 = 效果。而REGEXP在列值内进行匹配,如果被匹配的文本在列值中出现,REGEXP将会找到它,相应的行将被返回。这是一个非常重要的差别。
REGEXP也可以通过使用^和$定位符(anchor)来匹配整个列值。
使用 BINARY 关键字,区分大小写:
SELECT prod_name FROM products WHERE prod_name REGEXP BINARY 'JetPack .000';
SELECT prod_name FROM products WHERE prod_name REGEXP BINARY 'jetPack .000';
2
3
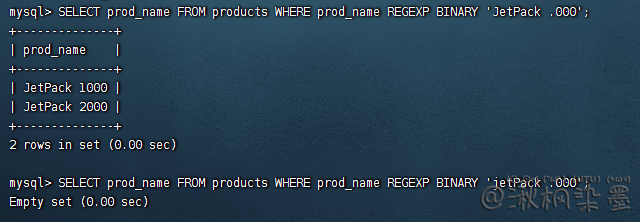
等同OR:
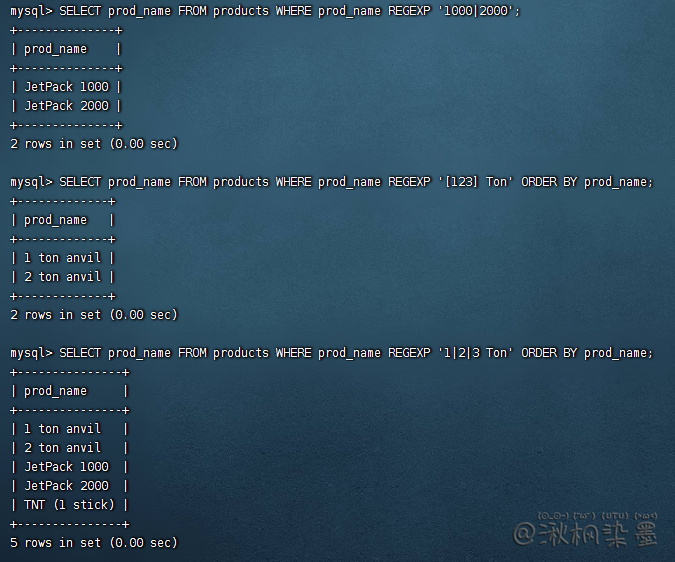
SELECT prod_name FROM products WHERE prod_name REGEXP '1000|2000';
SELECT prod_name FROM products WHERE prod_name REGEXP '[123] Ton' ORDER BY prod_name;
-- 上面的[123]等同[1|2|3]
SELECT prod_name FROM products WHERE prod_name REGEXP '1|2|3 Ton' ORDER BY prod_name;
-- 上面的语句,MySQL假定意思是'1'或'2'或'3 ton'。除非把|用[]包起来
2
3
4
5
匹配范围:
例如:[0123456789] 可以简化为 [0-9]
SELECT prod_name FROM products WHERE prod_name REGEXP '[1-5] Ton';
使用 \\ 转义:
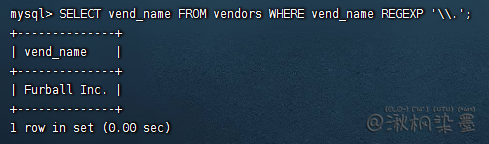
对于常见的 . | [ ] 等,如果需要查找这类符号,需要进行转义
匹配反斜杠()本身,需要使用 \\
SELECT vend_name FROM vendors WHERE vend_name REGEXP '\\.';
\\ 也用来引用元字符(具有特殊含义的字符)
| 元字符 | 说明 |
|---|---|
| \\f | 换页 |
| \\n | 换行 |
| \\r | 回车 |
| \\t | 制表 |
| \\v | 纵向制表 |
匹配字符类:
为了方便找出所有数字、字母字符或数字字母字符等的匹配。可以使用预定义的字符集,称为字符类(character class)
| 类 | 说明 |
|---|---|
| [:alnum:] | 任意字母和数字(同[a-zA-Z0-9]) |
| [:alpha:] | 任意字符(同[a-zA-Z]) |
| [:blank:] | 空格和制表(同[\t]) |
| [:cntrl:] | ASCII控制字符(ASCII 0到31和127) |
| [:digit:] | 任意数字(同[0-9]) |
| [:graph:] | 与[:print:]相同,但不包括空格 |
| [:lower:] | 任意小写字母(同[a-z]) |
| [:print:] | 任意可打印字符 |
| [:punct:] | 既不在[:alnum:]又不在[:cntrl:]中的任意字符 |
| [:space:] | 包括空格在内的任意空白字符(同[\\f\\n\\r\\t\\v]) |
| [:upper:] | 任意大写字母(同[A-Z]) |
| [:xdigit:] | 任意十六进制数字(同[a-fA-F0-9]) |
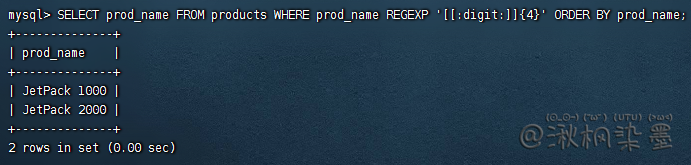
SELECT prod_name FROM products WHERE prod_name REGEXP '[[:digit:]]{4}' ORDER BY prod_name;
匹配多个实例:
| 元字符 | 说明 |
|---|---|
| * | 0个或多个匹配 |
| + | 1个或多个匹配(等于{1,}) |
| ? | 0个或1个匹配(等于{0,1}) |
| {n} | 指定数目的匹配 |
| {n,} | 不少于指定数目的匹配 |
| {n,m} | 匹配数目的范围(m不超过255) |
SELECT prod_name FROM products WHERE prod_name REGEXP '\\([0-9] sticks?\\)' ORDER BY prod_name;
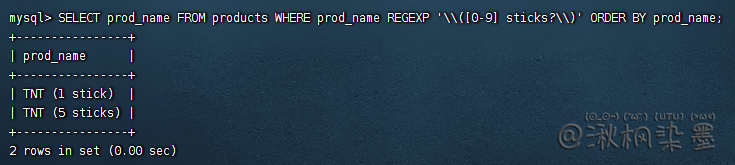
sticks?:匹配 stick 和 sticks (s后的?使s可选,出现0或1次)
定位符:
匹配特定位置的文本
| 元字符 | 说明 |
|---|---|
| ^ | 文本的开始 |
| $ | 文本的结尾 |
| [[:<:]] | 词的开始 |
| [[:>:]] | 词的结尾 |
其中 ^ 具有两种用法,匹配串的开始,如果在集合中(用 [ ] 定义),用它来否定该集合。
SELECT prod_name FROM products WHERE prod_name REGEXP '^[0-9\\.]' ORDER BY prod_name;
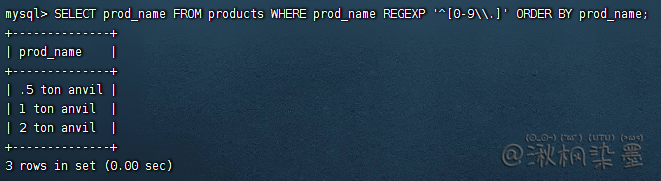
测试正则表达式:
可以在不使用数据库表的情况下用SELECT来测试正则表达式。REGEXP检查返回0(没有匹配) 或1(匹配)
SELECT 'hello' REGEXP '[0-9]';

# 3.11 创建计算字段
执行算术计算:
| 操作符 | 说明 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
SELECT prod_id, quantity, item_price, quantity*item_price AS expanded_price FROM orderitems;
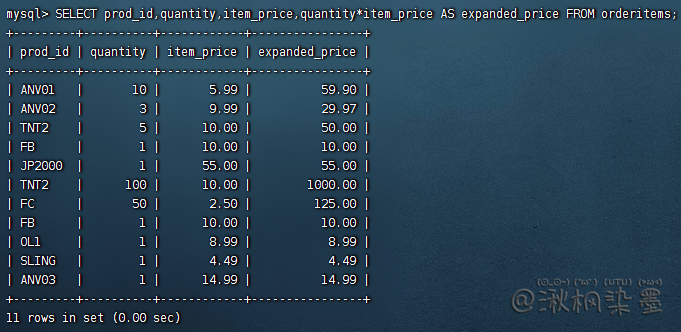
简单测试:
SELECT 3*2;
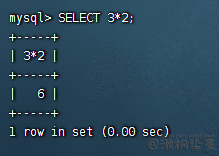
# 3.12 函数
主要类型函数:
- 用于处理文本串(如删除或者填充值,转换值为大写或小写)的文本函数
- 用于在数值数据上进行算术操作(如返回绝对值,进行代数运算)的数值函数
- 用于处理日期和时间值并从这些值中提取特定成分(例如,返回两个日期之差,检查日期有效性等)的日期和时间函数
- 返回DBMS正使用的特殊信息(如返回用户登录信息,检查版本细节)的系统函数
文本处理函数
| 函 数 | 说 明 | 示 例 |
|---|---|---|
| Char_length(s) | 返回字符串s的字符数 | SELECT Char_length('你好123') - 5 |
| Concat(s1, s2, ...) | 将字符串s1,s2等多个字符串合并为一个字符串 | SELECT Concat('a','b','c') - abc |
| Concat_ws(x, s1, s2, ...) | 同Concat(s1, s2, ...)函数,但是每个字符串直接要加上x | SELECT Concat_ws('/', 'a', 'b', 'c') - a/b/c |
| Convert(s using code) | 将s字符串转换成code编码格式 | SELECT CONVERT('中' USING latin1) - ? |
| Field(s, s1, s2, ...) | 返回第一个字符串s在字符串列表(s1,s2,...)中的位置 | SELECT Field('c', 'a', 'b', 'c', 'd') - 3 |
| Find_in_set(s1, s2) | 返回在字符串s2中与s1匹配的字符串的位置 | SELECT Find_in_set('c','a,b,c,d,e') - 3 |
| Format(x, n) | 将数字 x 格式化 "#,###.##", 将 x 保留到小数点后 n 位,最后一位四舍五入 | SELECT Format(250500.5646, 2) - 250,500.56 |
| Insert(s1, x, len, s2) | 字符串 s2 替换 s1 的 x 位置开始长度为 len 的字符串 | SELECT Insert("google.com", 1, 2, "mysql") - mysqlogle.com |
| Lcase(s) | 将字符串 s 的所有字母变成小写字母 | SELECT Lcase('STRIng') - string |
| Left(s, n) | 返回字符串s的前n个字符 | SELECT Left('string', 2) - st |
| Length(s) | 返回字符串s的长度 | SELECT Length('你好123') - 9 |
| Load_file(file_name) | 读入文件并作为一个字符串返回文件内容 | |
| Locate(s1, s) | 从字符串 s 中获取 s1 的开始位置 | SELECT Locate('st','myteststring') - 5 |
| Lower(s) | 将字符串s的所有字母变成小写字母 | SELECT Lower('STring') - string |
| Lpad(s1, len, s2) | 在字符串 s1 的开始处填充字符串 s2,使字符串长度达到 len | SELECT Lpad('abc', 6, 'xx') - xxxabc |
| LTrim(s) | 去掉字符串 s 开始处的空格 | SELECT LTrim(' abc') - abc |
| Mid(s, n, len) | 从字符串 s 的 n 位置截取长度为 len 的子字符串 | SELECT Mid("abcdef", 2, 3) - bcd |
| Position(s1 IN s) | 从字符串 s 中获取 s1 的开始位置 | SELECT Position('b' in 'abc') - 2 |
| Repeat(s, n) | 将字符串s重复n次 | SELECT Repeat('abc', 3) - abcabcabc |
| Replace(s, s1, s2) | 将字符串s2替代字符串s中的字符串s1 | SELECT Replace('abc', 'a', 'x') - xbc |
| Reverse(s) | 将字符串s的顺序反过来 | SELECT Reverse('abc') - cba |
| Right(s, n) | 返回字符串s的后n个字符 | SELECT Right('abcdef', 2) - ef |
| Rpad(s1, len, s2) | 在字符串 s1 的结尾处添加字符串 s2,使字符串的长度达到 len | SELECT Rpad('abc',6,'xx') - abcxxx |
| RTrim(s) | 去掉字符串 s 结尾处的空格 | SELECT RTrim('abc ') - abc |
| Soundex() | 返回串的SOUNDEX值 | |
| Space(n) | 返回n个空格 | SELECT Space(2) |
| Strcmp(s1, s2) | 比较字符串 s1 和 s2,如果 s1 与 s2 相等返回 0 ,如果 s1>s2 返回 1,如果 s1<s2 返回 -1 | SELECT Strcmp('abd', 'abce') - 1 |
| Substr/Substring(s, start, length) | 从字符串 s 的 start 位置截取长度为 length 的子字符串 | SELECT Substring('abcdef', 2, 3) - bcd |
| Trim(s) | 去掉字符串 s 开始和结尾处的空格 | SELECT Trim(' abc ') - abc |
| Ucase(s) | 将字符串转换为大写 | SELECT Ucase('STring') - STRING |
| Upper(s) | 将字符串转换为大写 | SELECT Upper('STring') - STRING |
其中SOUNDEX是一个将任何文本串转换为描述其语音表示的字母数字模式的算法。SOUNDEX考虑了类似的发音字符和音节,使得能对串进行发音比较而不是字母比较。
例如,一个查询内容Y.Lee,实际为Y.Lie:
SELECT cust_name, cust_contact FROM customers WHERE Soundex(cust_contact) = Soundex('Y Lie');

日期和时间处理函数
| 函 数 | 说 明 | 示 例 |
|---|---|---|
| AddDate(d, n) | 计算日期d加上n天的日期 | SELECT AddDate("2022-03-25", INTERVAL 10 DAY) - 2022-04-04 |
| AddTime(t, n) | 时间 t 加上时间表达式 n | SELECT AddTime("2020-06-15 09:34:21", "2:10:5") - 2020-06-15 11:44:26 |
| CurDate()/Current_date() | 返回当前日期的年月日 | SELECT CurDate() - 2022-05-18 |
| Current_timestamp() | 返回当前日期和时间 | SELECT Current_timestamp() - 2022-05-18 14:45:31 |
| CurTime()/Current_time() | 返回当前时间的时分秒 | SELECT CurTime() - 14:41:17 |
| Date() | 从日期或日期时间表达式中提取日期值 | SELECT DATE("2022-05-18 14:45:31") - 2022-05-18 |
| DateDiff(d1, d2) | 计算日期d1到d2之间相隔的天数 | SELECT DateDiff('2001-01-01', '2001-02-02') - -32 |
| Date_Add(d, INTERVAL expr type) | 计算起始日期 d 加上一个时间段后的日期 | SELECT Date_add("2017-06-15 09:34:21", INTERVAL 15 MINUTE) - 2017-06-15 09:49:21 |
| Date_format() | 按表达式 f 的要求显示日期 d | SELECT Date_format('2011-11-11 11:11:11', '%Y/%m/%d %r') - 2011/11/11 11:11:11 AM |
| Date_sub(d, f) | 函数从日期减去指定的时间间隔 | SELECT Date_sub("2022-03-25", INTERVAL 10 DAY) - 2022-03-15 |
| Day() | 返回一个日期的天数部分 | SELECT Day("2022-05-18") - 18 |
| Dayname(d) | 返回日期d是星期几,如 Monday,Tuesday | SELECT Dayname("2022-05-18") - Wednesday |
| DayOfMonth(d) | 计算日期d是本月的第几天 | SELECT DayOfMonth("2022-05-18") - 18 |
| DayOfWeek(d) | 日期d今天是星期几,1星期日,2星期一 | SELECT DayOfWeek("2022-05-18") - 4 |
| DayOfYear(d) | 计算日期d是本年的第几天 | SELECT DayOfYear("2022-05-18") - 138 |
| Extract(type FROM d) | 从日期 d 中获取指定的值,type 指定返回的值 | SELECT Extract(YEAR FROM '2011-11-11 11:11:11') - 2011 |
| From_days(t) | 计算从 0000 年 1 月 1 日开始 n 天后的日期 | SELECT From_days(1111) - 0003-01-16 |
| From_unixtime(10位时间戳) | 将unix时间戳转换为2017-03-24 11:15:05的格式 | SELECT From_unixtime(1652889852) - 2022-05-18 16:04:12 |
| Hour(d) | 返回d中的小时值 | SELECT Hour('2022-05-18 16:05:23') - 16 |
| Last_day(d) | 返回给给定日期的那一月份的最后一天 | SELECT Last_day('2022-05-18 16:05:23') - 2022-05-31 |
| LocalTime()/LocalTimestramp() | 返回当前日期和时间 | SELECT LocalTime() - 2022-05-18 16:09:33 |
| MakeDate(year, day-of-year) | 基于给定参数年份 year 和所在年中的天数序号 day-of-year 返回一个日期 | SELECT MakeDate(2022, 32) - 2022-02-01 |
| MakeTime(hour, minute, second) | 组合时间,参数分别为小时、分钟、秒 | SELECT MaleTime(9, 8, 7) - 09:08:07 |
| Microsecond(date) | 返回日期参数所对应的微秒数 | SELECT Microsecond('2022-05-19 09:34:00.000023') - 23 |
| Minute(d) | 返回d中的分钟值 | SELECT Minute('2022-05-19 09:34:01') - 34 |
| Month(d) | 返回日期d中的月份值 | SELECT Month('2022-05-19 09:34:01') - 5 |
| Monthname(d) | 返回日期当中的月份名称,如 Janyary | SELECT Monthname('2022-05-19 09:34:01') - May |
| Now() | 返回当前日期和时间 | SELECT Now() - 2022-05-18 16:16:25 |
| Period_add(period, number) | 为 年-月 组合日期添加一个时段 | SELECT Period_add(202201, 5) - 202206 |
| Period_diff(period1, period2) | 返回两个时段之间的月份差值 | SELECT Period_diff(201710, 201703) - 7 |
| Quarter(d) | 返回日期d是第几季节,返回1~4 | SELECT QUARTER('2011-11-11 11:11:11') - 4 |
| Second(d) | 返回d中的秒钟值 | SELECT Second('1:2:3') - 3 |
| Sec_to_time(s) | 将以秒为单位的时间 s 转换为时分秒的格式 | SELECT Sec_to_time(4320) - 01:12:00 |
| Str_to_date(string, format) | 将字符串转变为日期 | SELECT Str_to_date("August 10 2017", "%M %d %Y") - 2017-08-10 |
| Subdate(d, n) | 日期d减去n天后的日期 | SELECT Subdate('2011-11-11 11:11:11', 1) - 2011-11-10 11:11:11 |
| SubTime(t,n) | 时间 t 减去 n 秒的时间 | SELECT SubTime('2011-11-11 11:11:11', 5) - 2011-11-11 11:11:06 |
| Time(d) | 返回一个日期时间的时间部分 | SELECT Time('2011-11-11 11:11:11') - 11:11:11 |
| Time_format(t, f) | 按表达式 f 的要求显示时间 t | SELECT Time_format('11:11:11', '%r') - 11:11:11 AM |
| Time_to_sec(t) | 将时间 t 转换为秒 | SELECT Time_to_sec('1:12:00') - 4320 |
| TimestampDiff(unit, expr1, expr2) | 计算时间差,返回 expr2 − expr1 的时间差 | SELECT TimestampDiff(MONTH, '2003-02-01', '2003-05-01') - 3 |
| Unix_timestamp() | 以UNIX时间戳的形式返回当前时间 | SELECT Unix_timestamp() - 1653306783 |
| Week(d) | 计算日期d是本年的第几个星期,范围是0~53 | SELECT Week('2011-11-11 11:11:11') - 45 |
| WeekDay(d) | 日期 d 是星期几,0 表示星期一,1 表示星期二 | SELECT WeekDay('2011-11-11 11:11:11') - 4 |
| Year() | 返回一个日期的年份部分 | SELECT Year("2017-06-15") - 2017 |
上面 AddDate 函数的例子中,INTERVAL 10 DAY,其中 DAY 可替换的其他值如下:
- MICROSECOND
- SECOND
- MINUTE
- HOUR
- DAY
- WEEK
- MONTH
- QUARTER
- YEAR
- SECOND_MICROSECOND
- MINUTE_MICROSECOND
- MINUTE_SECOND
- HOUR_MICROSECOND
- HOUR_SECOND
- HOUR_MINUTE
- DAY_MICROSECOND
- DAY_SECOND
- DAY_MINUTE
- DAY_HOUR
- YEAR_MONTH
MySQL首选日期格式:yyyy-MM-dd,如果一个字段为datetime类型来存储日期及时间值,如2021-01-01 11:11:11,那么直接用WHERE order_date = '2021-01-01'会匹配失败。
解决的办法是指示MySQL仅将给出的日期与列中的日期部分进行比较,而不是将给出的日期与整个列值进行比较
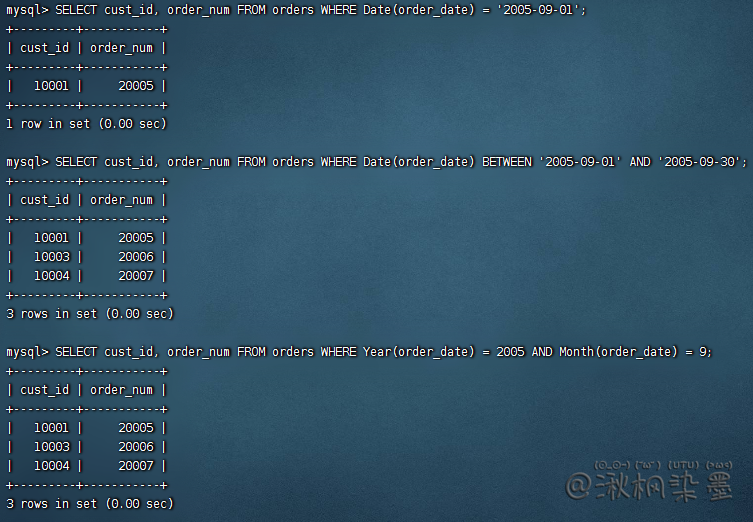
SELECT cust_id, order_num FROM orders WHERE Date(order_date) = '2005-09-01';
如果要检索2005年9月下的所有订单,该如何?
-- 方法1:
SELECT cust_id, order_num FROM orders WHERE Date(order_date) BETWEEN '2005-09-01' AND '2005-09-30';
-- 方法2:
SELECT cust_id, order_num FROM orders WHERE Year(order_date) = 2005 AND Month(order_date) = 9;
2
3
4
数学函数
| 函 数 | 说 明 | 示 例 |
|---|---|---|
| Abs(x) | 返回x的绝对值 | SELECT Abs(-1) - 1 |
| Acos(x) | 求 x 的反余弦值 | SELECT Acos(0.25) - 1.318116071652818 |
| Ceil/Ceiling(x) | 返回大于或等于x的最小整数 | SELECT Ceil(1.5) - 2 |
| Cos(x) | 求余弦值 | SELECT Cos(2) - -0.4161468365471424 |
| Cot(x) | 求余切值 | SELECT Cot(t) - -3.436353004180128 |
| Degrees | 将弧度转换为角度 | SELECT Degrees(3.1415926535898) - 180.0000000000004 |
| n Div m | 整除,n 为被除数,m 为除数 | SELECT 10 DIV 5 - 2 |
| Exp(x) | 返回e的x次方 | SELECT Exp(3) - 20.085536923187668 |
| Floor(x) | 返回小于或等于x的最大整数 | SELECT Floor(1.5) - 1 |
| Greatest(s1, s2, s3, ...) | 返回列表中的最大值 | SELECT Greatest(3, 12, 34, 8, 25) - 34 |
| Least(s1, s2, s3, ...) | 返回列表中的最小值 | SELECT Least(3, 12, 34, 8, 25) - 3 |
| Ln | 返回数字的自然对数,以 e 为底 | SELECT Ln(2) - 0.6931471805599453 |
| LOG(x)/LOG(base, x) | 返回自然对数(以 e 为底的对数),如果带有 base 参数,则 base 为指定带底数 | SELECT Log(2, 4) - 2 |
| Log10(x) | 返回以 10 为底的对数 | SELECT Log10(100) - 2 |
| Log2(x) | 返回以 2 为底的对数 | SELECT Log2(4) - 2 |
| Mod(x,y) | 返回x除以y之后的余数 | SELECT mod(5, 3) - 2 |
| Pi() | 返回圆周率(3.141593) | SELECT Pi() - 3.141593 |
| Pow/Power(x,y) | 返回x的y次方 | SELECT power(2,3) - 8 |
| Radians(x) | 将角度转换为弧度 | SELECT Radians(180) - 3.141592653589793 |
| Rand() | 返回一个0~1随机数 | SELECT Rand() - 0.6084506638426805 |
| Round(x) | 返回离x最近的整数 | SELECT Round(1.23456) - 1 |
| Round(x,y) | 保留x小数点后y位的值,但截断时要进行四舍五入 | SELECT Round(1.23456,3) - 1.235 |
| Sign(x) | 返回x的符号,-1代表x为负数、0代表0、1代表正数 | SELECT Sign(-10) - -1 |
| Sin(x) | 求正弦值 | SELECT Sin(Radians(30)) - 0.49999999999999994 |
| Sqrt(x) | 返回x的平方根 | SELECT Sqrt(25) - 5 |
| Tan() | 求正切值 | SELECT Tan(1.75) - -5.52037992250933 |
| Truncate(x,y) | 返回数值x保留到小数点后y位的值 | SELECT Truncate(1.23456,3) - 1.234 |
条件判断
| 函 数 | 说 明 |
|---|---|
| Case expression WHEN condition1 THEN result1 ... ELSE result END | 相当于Java中的switch |
| If(expr, v1, v2) | 如果表达式 expr 成立,返回结果 v1;否则,返回结果 v2 |
| IfNull(v1,v2) | 如果v1的值不为NULL,则返回v1,否则返回v2 |
| IsNull(expression) | 判断表达式是否为 NULL |
| NullIf(expr1, expr2) | 比较两个字符串,如果字符串 expr1 与 expr2 相等 返回 NULL,否则返回 expr1 |
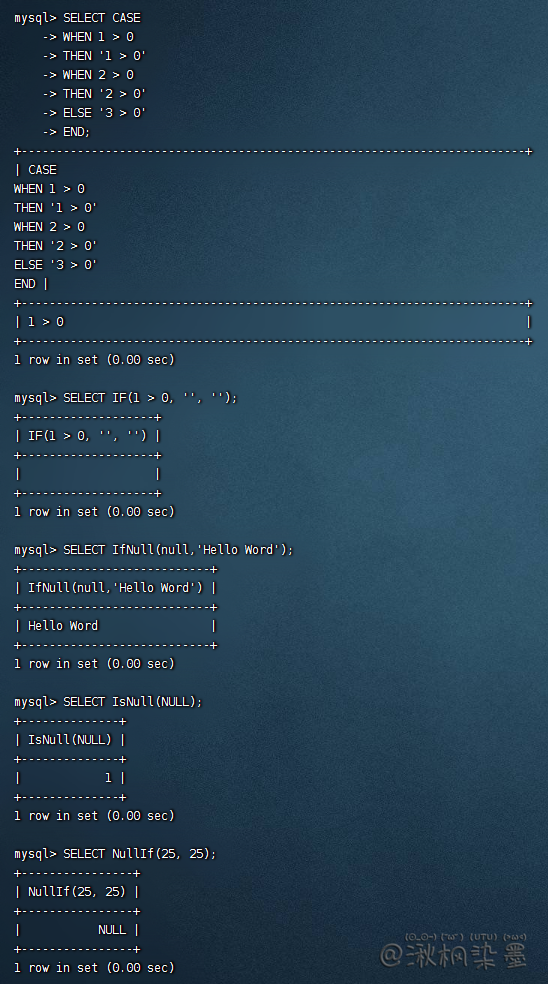
-- CASE
SELECT CASE
WHEN 1 > 0
THEN '1 > 0'
WHEN 2 > 0
THEN '2 > 0'
ELSE '3 > 0'
END;
-- IF
SELECT IF(1 > 0, '正确', '错误');
-- IfNull
SELECT IfNull(null,'Hello Word');
-- IsNull
SELECT IsNull(NULL);
-- NullIf
SELECT NullIf(25, 25);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
系统信息函数
| 函 数 | 说 明 | 示 例 |
|---|---|---|
| Current_user() | 返回当前用户 | SELECT Current_user() - root@% |
| Database() | 返回当前数据库名 | SELECT Database() - ccj_test |
| Last_insert_id() | 返回最近生成的AUTO_INCREMENT值 | SELECT Last_insert_id() - 1010 |
| SESSION_USER()/SYSTEM_USER()/User() | 返回当前用户 | SELECT User() - root@127.0.0.1 |
| Version() | 返回数据库的版本号 | SELECT Version() - 5.7.37 |
加密函数
| 函 数 | 说 明 | 示 例 |
|---|---|---|
| Aes_encrypt(str, key) | 返回用密钥key对字符串str利用高级加密标准算法加密后的结果,调用AES_ENCRYPT的结果是一个二进制字符串,以BLOB类型存储 | SELECT To_base64(Aes_Encrypt('root', 'lgcxRwsy3eaaMmze')) - 2MK/0GN1COlFYTu754aZwA== |
| Aes_decrypt(str, key) | 返回用密钥key对字符串str利用高级加密标准算法解密后的结果 | SELECT Aes_decrypt(From_base64('2MK/0GN1COlFYTu754aZwA=='), 'lgcxRwsy3eaaMmze') - root |
| Decode(str, key) | 使用key作为密钥解密加密字符串str | SELECT To_base64(Decode('root', 'lgcxRwsy3eaaMmze')) - uNCt9g== |
| Encrypt(str,salt) | 使用UNIXcrypt()函数,用关键词salt(一个可以惟一确定口令的字符串,就像钥匙一样)加密字符串str | SELECT ENCRYPT('root','salt') - saFKJij3eLACw |
| Encode(str,key) | 使用key作为密钥加密字符串str,Encode()的结果是一个二进制字符串,它以BLOB类型存储 | SELECT Encode(From_base64('uNCt9g=='), 'lgcxRwsy3eaaMmze') - root |
| Md5(str) | 计算字符串str的MD5校验和 | SELECT Md5('123456') - e10adc3949ba59abbe56e057f20f883e |
| Password(str) | 返回字符串str的加密版本,这个加密过程是不可逆转的,和UNIX密码加密过程使用不同的算法 | SELECT Password('123456') - *6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9 |
| Sha(str) | 计算字符串str的安全散列算法(SHA)校验和 | SELECT Sha('123456') - 7c4a8d09ca3762af61e59520943dc26494f8941b |
# 3.13 聚集函数
| 函 数 | 说 明 |
|---|---|
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值之和 |
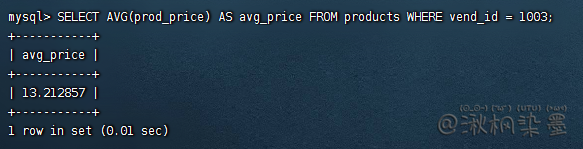
AVG() 自动忽略NULL行,可同时用多个AVG()函数
SELECT AVG(prod_price) AS avg_price FROM products WHERE vend_id = 1003;
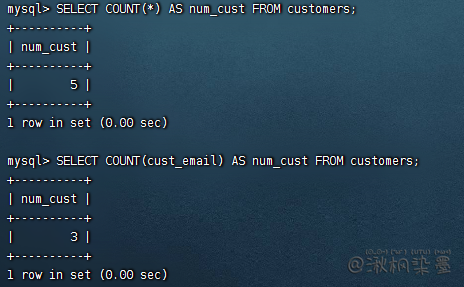
COUNT(*) 和 COUNT(1) 对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值
COUNT(column)对特定列中具有值的行进行计数,忽略NULL值
SELECT COUNT(*) AS num_cust FROM customers;
SELECT COUNT(cust_email) AS num_cust FROM customers;
2
可以找出最大的数值或日期值,但MySQL允许将他用来返回任意列中的最大值,包括文本列中的最大值。
在用于文本数据时,如果数据按相同的列排序,则返回最后一行。
SELECT MAX(prod_price) AS max_price FROM products;
SELECT MIN(prod_price) AS min_price FROM products;
2
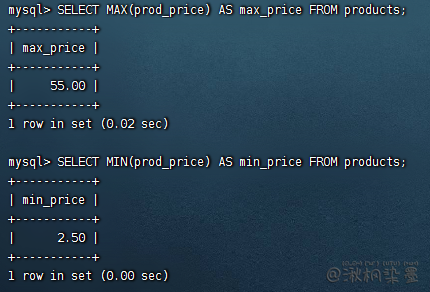
SUM() 自动忽略NULL的行
SELECT SUM(quantity) AS items_ordered FROM orderitems WHERE order_num = 20005;
SELECT SUM(item_price*quantity) AS total_price FROM orderitems WHERE order_num = 20005;
2
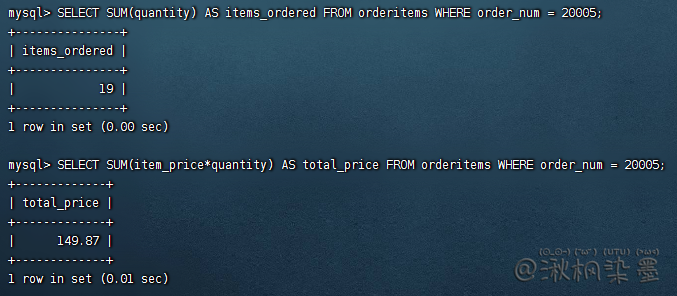
配合DISTINCT
默认ALL
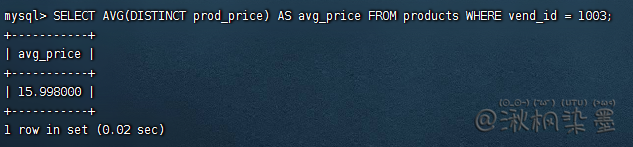
SELECT AVG(DISTINCT prod_price) AS avg_price FROM products WHERE vend_id = 1003;
组合聚合函数
SELECT COUNT(*) AS num_items, MIN(prod_price) AS price_min, MAX(prod_price) AS price_max, AVG(prod_price) AS price_avg FROM products;

# 3.14 分组
统计每个供货商有多少个产品:
SELECT vend_id, COUNT(*) AS num_prods FROM products GROUP BY vend_id;
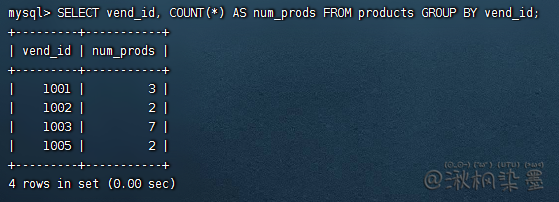
说明:
- GROUP BY子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制。
- 如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)
- GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名。
- 除聚集计算语句外,SELECT语句中的每个列都必须在GROUP BY子句中给出。
- 如果分组列中具有NULL值,则NULL将作为一个分组放回。如果列中有多行NULL值,他们将分为一组。
- GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
WITH ROLLUP
可以得到每个分组以及每个分组汇总级别(针对每个分组)
SELECT vend_id, COUNT(*) AS num_prods FROM products GROUP BY vend_id WITH ROLLUP;

最后多了一行
过滤分组:
WHERE过滤指定的行而不是分组,所以WHERE不能用来过滤分组
HAVING非常类似WHERE。事实上,目前为止所学过的所有类型的WHERE子句都可以用HAVING来替代。
唯一的区别是WHERE过滤行,而HAVING过滤分组。
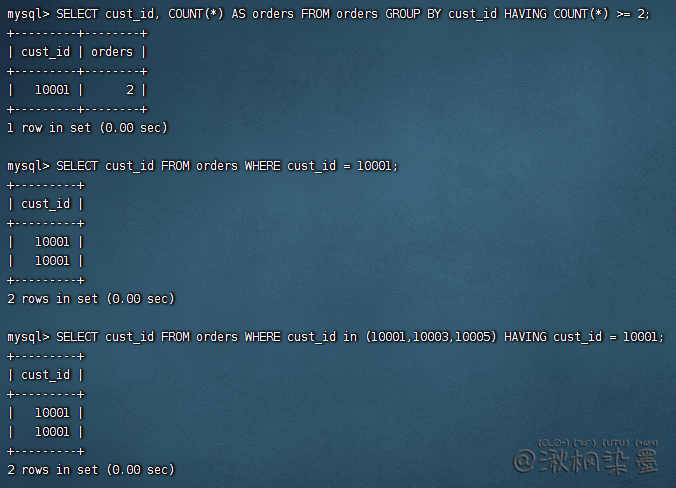
SELECT cust_id, COUNT(*) AS orders FROM orders GROUP BY cust_id HAVING COUNT(*) >= 2;
SELECT cust_id FROM orders WHERE cust_id = 10001;
SELECT cust_id FROM orders WHERE cust_id in (10001,10003,10005) HAVING cust_id = 10001;
2
3
HAVING和WHERE的区别:
这里是另一种理解方法,WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。这是一个重要区别,WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。
例:返回2个(含)下单以上,价格10(含)以上
SELECT vend_id, COUNT(*) AS num_prods FROM products WHERE prod_price >= 10 GROUP BY vend_id HAVING COUNT(*) >= 2;

一般在使用GROUP BY子句时,应该也给出ORDER BY子句。这是保证数据正确排序的唯一方法。千万不要仅依赖GROUP BY排序数据
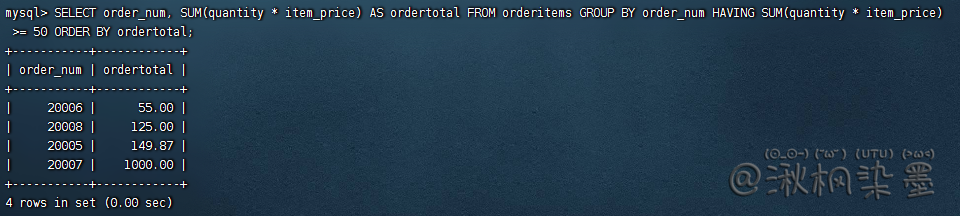
SELECT order_num, SUM(quantity * item_price) AS ordertotal FROM orderitems GROUP BY order_num HAVING SUM(quantity * item_price) >= 50 ORDER BY ordertotal;
# 3.15 使用顺序
| 子 句 | 说 明 | 是否必须使用 |
|---|---|---|
| SELECT | 要返回的列或表达式 | 是 |
| FROM | 从中检索数据的表 | 仅在从表选择数据时使用 |
| WHERE | 行级过滤 | 否 |
| GROUP BY | 分组说明 | 仅在按组计算聚集时使用 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 输出排序顺序 | 否 |
| LIMIT | 要检索的行数 | 否 |
# 四:DML
# 4.1 插入数据
几种使用方式:
- 插入完整的行
- 插入行的一部分
- 插入多行
- 插入某些查询的结果
INSERT语句一般不产生输出,但是可以看到插入的行数。例如下面的运行截图为成功插入两行。

插入完整的行
-- 无值的列用NULL(前提必须是该列能允许为NULL或自增长等)
INSERT INTO customers VALUES (NULL, 'Pep E. LaPew', '100 Main Street', 'Los Angeles', 'CA', '90046', 'USA', NULL, NULL);
2
缺点:高度依赖于表中列的定义次序,也不能保证下一次表结构变动后各个列保持完全相同次序
更安全却更繁琐
INSERT INTO customers(cust_name, cust_address, cust_city, cust_state, cust_zip, cust_country, cust_contact, cust_email)
VALUES('Pep E. LaPew', '100 Main Street', 'Los Angeles', 'CA', '90046', 'USA', NULL, NULL);
2
提高整体性能
INSERT操作可能很耗时(特别是有很多索引需要更新时),而且它可能降低等待处理的SELECT语句的性能。
如果数据检索是最重要的,则你可以通过在INSERT和INTO之前添加关键字 LOW_PRIORITY,指示MySQL降低INSERT语句的优先级:
该关键字同样适用于 UPDATE 和 DELETE 语句
INSERT LOW_PRIORITY INTO customers(cust_name, cust_address, cust_city, cust_state, cust_zip, cust_country, cust_contact, cust_email)
VALUES('Pep E. LaPew', '100 Main Street', 'Los Angeles', 'CA', '90046', 'USA', NULL, NULL);
2
插入多行
INSERT INTO customers(cust_name, cust_address, cust_city, cust_state, cust_zip, cust_country, cust_contact, cust_email)
VALUES('Pep E. LaPew', '100 Main Street', 'Los Angeles', 'CA', '90046', 'USA', NULL, NULL)
VALUES('M. Martian', '42 Galaxy Way', 'New York', 'NY', '11213', 'USA');
2
3
插入检索出的数据
-- 如果表为空,则没有行被插入,也不产生错误
INSERT INTO custnew(cust_id, cust_name, cust_address, cust_city, cust_state, cust_zip, cust_country, cust_contact, cust_email)
SELECT (cust_id, cust_name, cust_address, cust_city, cust_state, cust_zip, cust_country, cust_contact, cust_email) FROM customers;
2
3
最好在INSERT和SELECT用相同的列名(哪怕是别名)
事实上,MySQL甚至不关心SELECT返回的列名。它使用的是列的位置,因此SELECT中的第一列(不管其列名)将用来填充表列中指定的第一个列,第二列将用来填充表列中指定的第二个列,如此等等。这对于从使用不同列名的表中导入数据是非常直观有用的。
# 4.2 更新
与INSERT语句一样,一般不产生输出,但是可以看到更行的行数。例如下面的运行截图为成功更新两行。

UPDATE customers SET cust_email = 'elmer@fudd.com', cust_name = 'The Fudds' WHERE cust_id = 1005;
IGNORE
如果用UPDATE语句更新多行,并且在更新这些行中的一行或多行时出一个现错误,则整个UPDATE操作被取消(错误发生前更新的所有行被恢复到它们原来的值)。为即使是发生错误,也继续进行更新,可使用IGNORE关键字
UPDATE IGNORE customers SET cust_email = 'elmer@fudd.com', cust_name = 'The Fudds' WHERE cust_id = 1005;
使用子查询
UPDATE customers c SET c.cust_email = 'elmer@fudd.com' WHERE c.cust_id = (SELECT MAX(o.cust_id) FROM orders o);

如果把上面的orders表,更改为customers,就会报错
UPDATE customers c SET c.cust_email = 'elmer@fudd.com' WHERE c.cust_id = (SELECT MAX(o.cust_id) FROM customers o);

报错原因:mysql update时,更新的表不能在set和where中用于子查询
所以,可以将上面的语句,修改为
UPDATE customers c,
(SELECT MAX(cust_id) as cust_id FROM customers) o
SET c.cust_email = 'elmer@fudd.com' WHERE c.cust_id = o.cust_id;
2
3

# 4.3 删除数据
与INSERT语句一样,一般不产生输出,但是可以看到删除的行数。例如下面的运行截图为成功删除七行。

删除特定的行
DELETE FROM customers WHERE cust_id = 10006;
删除全部
DELETE FROM customers
如果想要更快的删除,可以使用 TRUNCATE TABLE 语句
TRUNCATE TABLE customers;
TRUNCATE TABLE(实际删除原表并重新创建一个表,而不是逐行删除表中的数据)
所以,如果表id自增长,使用DELETE删除所有数据,id依旧会继续增加,如果使用TRUNCATE,id从1开始
# 五:参考文献
- 《MySQL 是怎样运行的 - 小孩子4919》
- 《MySQL 必知必会 - Ben Forta著(刘晓霞、钟鸣)译》
- 官方文档 (opens new window)
- MySQL 函数 (opens new window)
- 超全整理,MySQL常用函数 (opens new window)