
摘要
Mysql Version:5.7.36
# 一:连接
运行着的服务器程序和客户端程序本质上都是计算机上的一个进程,所以客户端进程向服务器进程发送请求并得到回复的过程本质上是一个进程间通信的过程 !MySQL 支持下边三种客户端进程和服务器进程的通信方式。
# 1.1 TCP/IP
MySQL 采用 TCP 作为服务器和客户端之间的网络通信协议。在网络环境下,每台计算机都有一个唯一的IP地址,如果某个进程有需要采用 TCP 协议进行网络通信方面的需求,可以向操作系统申请一个端口号,这是一个整数值,它的取值范围是0~65535。这样在网络中的其他进程就可以通过 IP地址 + 端口号 的方式来与这个进程连接,这样进程之间就可以通过网络进行通信了。
# 1.2 命名管道和共享内存
如果是 Windows 用户,那么客户端进程和服务器进程之间可以考虑使用 命名管道 或 共享内存 进行通信。不过启用这些通信方式的时候需要在启动服务器程序和客户端程序时添加一些参数:
使用命名管道进行通信,需要在启动服务器程序的命令中加上
--enable-named-pipe参数,然后在启动客户端程序的命令中加入--pipe或--protocol=pipe参数。使用共享内存进行通信,需要在启动服务器程序的命令中加上
--shared-memory参数,然后在启动客户端程序的命令中加入--protocol=memory参数。不过需要注意的是,使用该方式,服务器进程和客户端进程必须在同一台 Windows 主机中。
# 1.3 Unix域套接字文件
如果 服务器进程和客户端进程 都运行在同一台操作系统为类Unix的机器上的话,可以使用 Unix域套接字文件 来进行进程间通信。如果在启动客户端程序时指定主机名为 localhost,或指定了 --protocol=socket 的启动参数,那服务器程序和客户端程序之间就可以通过Unix域套接字文件来进行通信了。
MySQL服务器程序默认监听的Unix域套接字文件路径为 /tmp/mysql.sock,客户端程序也默认连接到这个Unix域套接字文件。如果我们想改变这个默认路径,可以在启动服务器程序时指定socket 参数 mysqld --socket=/tmp/a.txt 这样服务器启动后便会监听 /tmp/a.txt。在服务器改变了默认的UNIX 域套接字文件后,如果客户端程序想通过UNIX 域套接字文件进行通信的话,也需要显式的指定连接到的UNIX域套接字文件路径 mysql -hlocalhost -uroot --socket=/tmp/a.txt -p 这样该客户端进程和服务器进程就可以通过路径为 /tmp/a.txt 的Unix 域套接字文件进行通信了。
# 二:请求
其实不论客户端进程和服务器进程是采用哪种方式进行通信,最后实现的效果都是:客户端进程向服务器进程发送一段文本(MySQL语句),服务器进程处理后再向客户端进程发送一段文本(处理结果)。
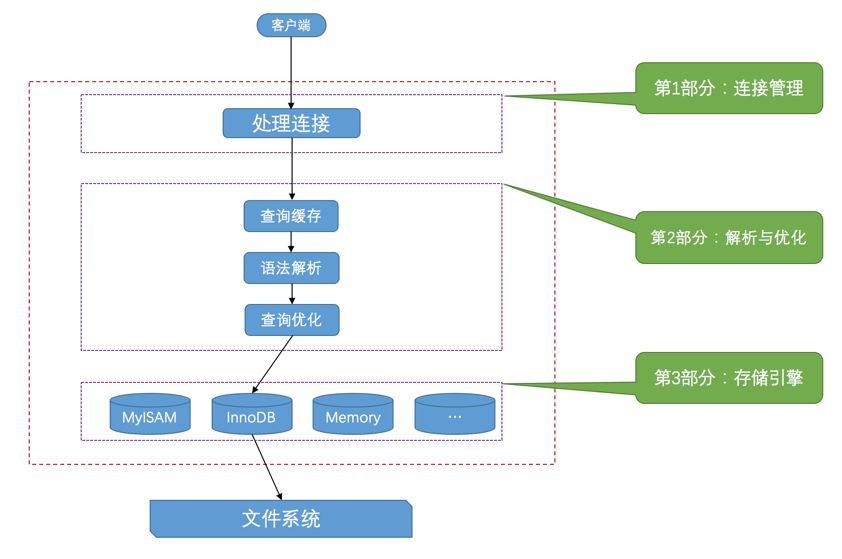
从图中可以看出,服务器程序处理来自客户端的查询请求大致需要经过三个部分,分别是 连接管理 、解析与优化 、存储引擎。
# 2.1 连接管理
客户端进程可以采用上边介绍的TCP/IP 、命名管道等方式来与服务器进程建立连接,每当有一个客户端进程连接到服务器进程时,服务器进程都会创建一个线程来专门处理与这个客户端的交互,当该客户端退出时会与服务器断开连接,服务器并不会立即把与该客户端交互的线程销毁掉,而是把它缓存起来,等另一个新的客户端进行连接时,把这个缓存的线程分配给它。这样就起到了不频繁创建和销毁线程的效果,从而节省开销。从这一点也能看出,MySQL 服务器会为每一个连接进来的客户端分配一个线程,但是线程分配的太多了会严重影响系统性能
在客户端程序发起连接的时,需要携带主机信息、用户名、密码,服务器程序会对客户端程序进行认证,如果认证失败,服务器程序会拒绝连接。另外,如果客户端程序和服务器程序不在同一台计算机上,还可以采用使用了SSL(安全套接字)的网络连接进行通信,来保证数据传输的安全性。
当连接建立后,与该客户端关联的服务器线程会一直等待客户端发送过来的请求,MySQL 服务器接收到的请求只是一个文本消息,该文本消息还要经过各种处理。
# 2.2 解析与优化
MySQL 服务器程序获取文本形式的请求后,接下来会经过一系列的处理,其中有几个比较重要的部分,分别是 查询缓存、语法解析 和 查询优化。
查询缓存
MySQL 服务器程序处理查询请求会把刚刚处理过的查询请求和结果缓存起来,如果下一次有一模一样的请求过来,直接从缓存中查找结果。而且可以在不同客户端之间共享。
如果两个查询请求在任何字符上的不同(例如:空格、注释、大小写),都会导致缓存不会命中。另外,如果查询请求中包含某些系统函数、用户自定义变量和函数、一些系统表(如 mysql、information_schema、performance_schema 数据库中的表)那这个请求就不会被缓存。
MySQL的缓存系统会监测涉及到的每张表,只要该表的结构或者数据被修改(INSERT、UPDATE、DELETE、TRUNCATE TABLE、ALTER TABLE、DROP TABLE 或 DROP DATABASE 语句),那使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除!
查询缓存有时可以提升系统性能,但也不得不因维护这块缓存而造成一些开销,比如每次都要去查询缓存中检索,查询请求处理完需要更新查询缓存,维护该查询缓存对应的内存区域。从MySQL 5.7.20开始,不推荐使用查询缓存,并在MySQL 8.0中删除。
语法解析
如果查询缓存没有命中,接下来就需要进入正式的查询阶段了。因为客户端程序发送过来的请求只是一段文本而已,所以 MySQL 服务器程序首先要对这段文本做分析,判断请求的语法是否正确,然后从文本中将要查询的表、各种查询条件都提取出来放到 MySQL 服务器内部使用的一些数据结构上来。
查询优化
语法解析之后,服务器程序获得到了需要的信息,比如要查询的列是哪些,表是哪个,搜索条件是什么等等,但光有这些是不够的,因为我们写的MySQL语句执行起来效率可能并不是很高,MySQL 的优化程序会对我们的语句做一些优化,如外连接转换为内连接、表达式简化、子查询转为连接等等。优化的结果就是生成一个执行计划,这个执行计划表明了应该使用哪些索引进行查询,表之间的连接顺序是啥样的。可以使用 EXPLAIN 语句来查看某个语句的执行计划。
# 2.3 存储引擎
截止到上面为止,服务器程序都还没有真正的去访问真实的数据表。MySQL服务器把数据的存储和提取操作都封装到了一个叫 存储引擎 的模块里。我们知道表是由一行一行的记录组成的,但这只是一个逻辑上的概念,物理上如何表示记录,怎么从表中读取数据,怎么把数据写入具体的物理存储器上,这都是存储引擎 负责的事情。为了实现不同的功能,MySQL 提供了各式各样的存储引擎,不同存储引擎管理的表具体的存储结构可能不同,采用的存取算法也可能不同。
为什么叫引擎呢?其实这个存储引擎以前叫做表处理器,后来可能人们觉得太土,就改成了存储引擎的叫法,它的功能就是接收上层传下来的指令,然后对表中的数据进行提取或写入操作。
为了管理方便,人们把 连接管理 、查询缓存 、语法解析 、查询优化 这些并不涉及真实数据存储的功能划分为MySQL server 的功能,把真实存取数据的功能划分为 存储引擎 的功能。各种不同的存储引擎向上边的 MySQL server 层提供统一的调用接口(也就是存储引擎API),包含了几十个底层函数,像 "读取索引第一条内容"、"读取索引下一条内容"、"插入记录" 等等。
所以在 MySQL server 完成了查询优化后,只需按照生成的执行计划调用底层存储引擎提供的API,获取到数据后返回给客户端就好了。
# 三:参考文献
- 《MySQL 是怎样运行的 - 小孩子4919》