
# 一:切换数据库
select dbIndex
许多关系型数据库,例如 MySQL 支持在一个实例下有多个数据库存在的,但是与关系型数据库用字符来区分不同数据库名不同,Redis 只是用数字作为多个数据库的实现。Redis 默认配置中是有16个数据库:
databases 16
假设 databases=16,select 0 操作将切换到第一个数据库,select 15 选择最后一个数据库,但是0号数据库和15号数据库之间的数据没有任何关联,甚至可以存在相同的键:
#默认进到0号数据库
> set hello world
OK
> get hello
"world"
#因为15号数据库和0号数据库是隔离的,所以get hello为空
> select 15
OK
#因为15号数据库和0号数据库是隔离的,所以get hello为空
[15]> get hello
(nil)
2
3
4
5
6
7
8
9
10
11
下图更加生动地表现出上述操作过程。同时可以看到,当使用 redis-cli -h{ip} -p{port} 连接Redis时,默认使用的就是0号数据库,当选择其他数据库时,会有 [index] 的前缀标识,其中index就是数据库的索引下标。
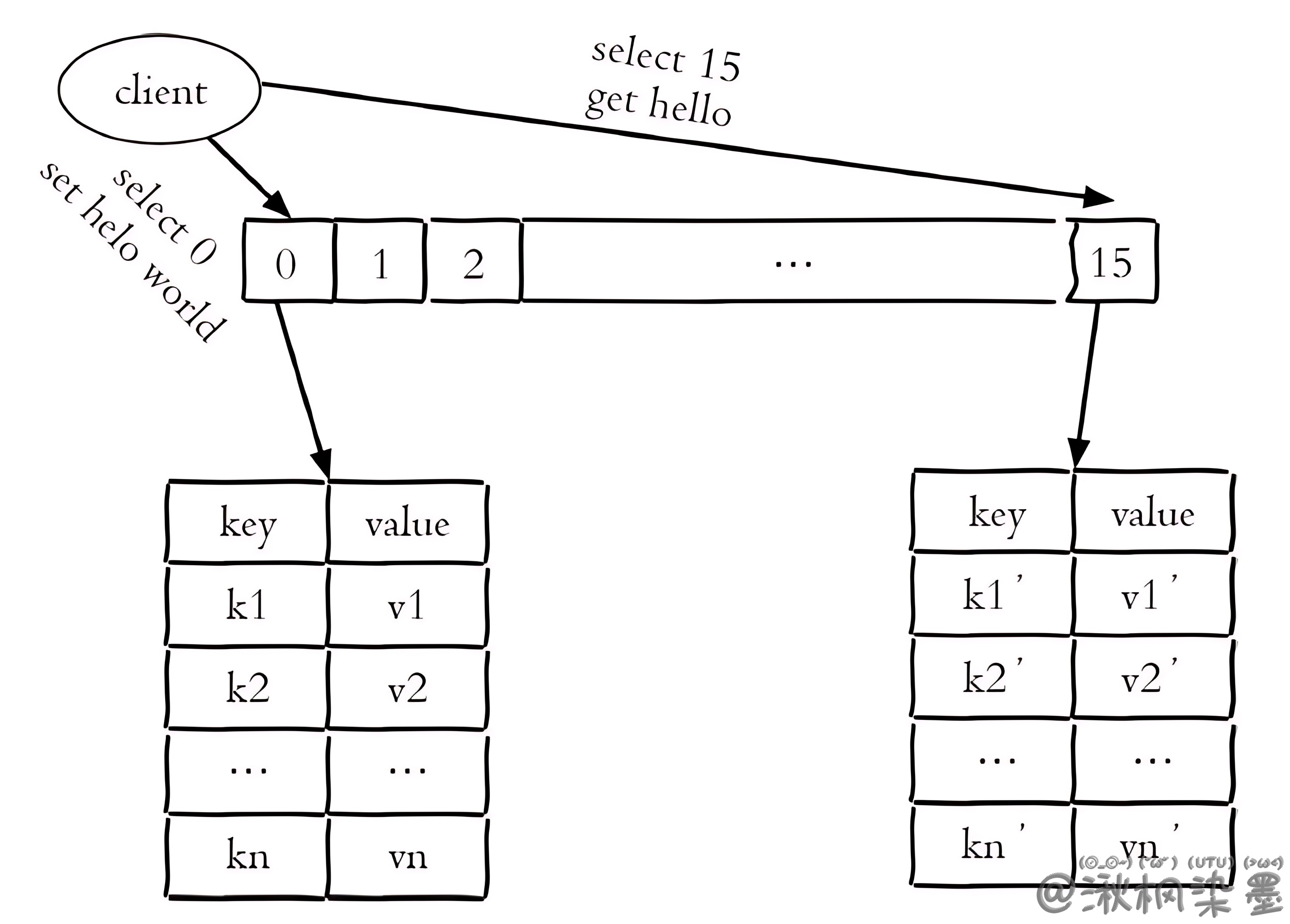
Q: 那么能不能像使用测试数据库和正式数据库一样,把正式的数据放在0号数据库,测试的数据库放在1号数据库,那么两者在数据上就不会彼此受影响了。事实真有那么好吗?
A: Redis3.0 中已经逐渐弱化这个功能,例如 Redis 的分布式实现 Redis Cluster 只允许使用0号数据库,只不过为了向下兼容老版本的数据库功能,该功能没有完全废弃掉,下面分析一下为什么要废弃掉这个 "优秀" 的功能呢?总结起来有三点:
- Redis 是单线程的。如果使用多个数据库,那么这些数据库仍然是使用一个CPU,彼此之间还是会受到影响的;
- 多数据库的使用方式,会让调试和运维不同业务的数据库变的困难,假如有一个慢查询存在,依然会影响其他数据库,这样会使得别的业务方定位问题非常的困难;
- 部分 Redis 的客户端根本就不支持这种方式。即使支持,在开发的时候来回切换数字形式的数据库,很容易弄乱。
建议: 如果要使用多个数据库功能,完全可以在一台机器上部署多个 Redis 实例,彼此用端口来做区分,因为现代计算机或者服务器通常是有多个 CPU 的。这样既保证了业务之间不会受到影响,又合理地使用了 CPU 资源。
# 二:flushdb/flushall
flushdb/flushall 命令用于清除数据库,两者的区别的是 flushdb 只清除当前数据库,flushall 会清除所有数据库
例如当前0号数据库有四个键值对、1号数据库有三个键值对:
> dbsize
(integer) 4
> select 1
OK
[1]> dbsize
(integer) 3
2
3
4
5
6
如果在0号数据库执行 flushdb,1号数据库的数据依然还在:
> flushdb
OK
> dbsize
(integer) 0
> select 1
OK
[1]> dbsize
(integer) 3
2
3
4
5
6
7
8
在任意数据库执行 flushall 会将所有数据库清除:
> flushall
OK
> dbsize
(integer) 0
> select 1
OK
[1]> dbsize
(integer) 0
2
3
4
5
6
7
8
flushdb/flushall命令可以非常方便的清理数据,但是也带来两个问题:
- flushdb/flushall 命令会将所有数据清除,一旦误操作后果不堪设想,通过
rename-command配置规避这个问题,以及如何在误操作后快速恢复数据。 - 如果当前数据库键值数量比较多,flushdb/flushall 存在阻塞 Redis 的可能性。
所以在使用flushdb/flushall一定要小心谨慎
# 三:rename-command
# 四:恢复数据
# 五:参考文献
- 《Redis深度历险:核心原理和应用实践 - 钱文品》
- 《Redis 开发与运维 - 付磊、张益军》
- 官方文档 (opens new window)