
摘要
工具:Notepad++ v7.9 (64-bit)
# 一:入门基础
# 1.1 匹配普通文本
| 说 明 | 正则表达式 | 文本及结果 |
|---|---|---|
| 匹配单结果 | example | This is a example |
| 匹配多结果 | example | This is a example, This is a example |
| 字母大小写 | this | This is a example, this is a example |
# 1.2 特殊字符
在正则表达式里,特殊字符(或字符集合)用来标示要搜索的东西。
| 特殊字符 | 说 明 | 正则表达式 | 文本及结果 |
|---|---|---|---|
. | 可以匹配任意单个字符(字母、数字等),不能匹配换行符 | sales. | sales.xlsorders3.xls sales2.xlscc sales3.xls |
\ | 用来转义 | .a..\. | sale.xlsorders3.xls ale.xls ccsales3.xls |
[] | 定义一个字符集合。在使用 [ 和 ] 定义的字符集合里,出现在 [ 和 ] 之间的所有字符都是该集合的组成部分,必须匹配其中某个成员 | [ns]a.\.xls | na1.xlssaa.xlsca1.xls u sa1.xls |
- | 连字符,定义字符区间,例如数字 [0123456789] 简化为 [0-9]26个大写字母简化为 [A-Z]字母+数字简化为 [A-Za-z0-9] | [ns]a[0-9]\.xls | na1.xlssaa.xls ca1.xls u sa1.xls |
^ | 排除某个字符集合 | [ns]a[^0-9]\.xls | na1.xlssaa.xlsca1.xls usa1.xls |
+ | 匹配某个字符(或字符集合)一次或多次重复 | [0-9]+ | 123@451223wabxs |
* | 匹配某个字符(或字符集合)零次或多次重复 | [0-9]+[a-z]* | 123@451223wabxs |
? | 匹配某个字符(或字符集合)零次或一次重复 | https?:// - 字符s至多出现一次 | The URL is http://qform.top to connect securely use https://qform.top instead |
{} | 为重复匹配次数设定一个区间范围 | [0-9]{2, 4}[a-z]{2} | 123@451223wabxs |
() | 作为子表达式,括号内的内容作为单体 | htt(ps)?:// | The URL is http://qform.top to connect securely use https://qform.top instead |
| | 或 | (19|20)\d{2} | 1967-08-17-214145-20145254 |
定义字符区间时,一定要避免让这个区间的尾字号小于它的首字符(例如
[3-1])。这样区间是没有意义的,而且往往会让整个模式失效。-是一种特殊的元字符,只有出现在 [ 和 ] 之间的时候才是元字符。在字符集合以外的地方,只是一个普通字符,只能与-本身匹配。因此,在正则表达式里,-字符不需要被转义。
例子一:
1001: $496.80
1002: $1290.69
1003: $26.43
1004: $613.42
1005: $7.61
1006: $414.90
1007: $25.00
2
3
4
5
6
7
正则表达式:[0-9]+: \$[0-9]{3,}\.[0-9]{2} - 简化 \d+: \$\d{3,}\.\d{2}(后面会介绍)
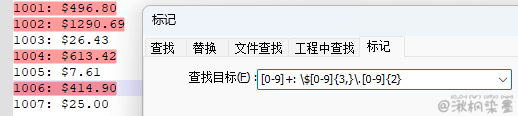
{3, } 表示至少重复3次
例子二:
This offer is not available to customers living in <b>AK</b> and <b>HI</b>.
正则表达式:<[Bb]>.*<\/[Bb]>

与预期结果不同,原因是被
.*一网打尽,这的确包含了我们想要匹配的文本,但其中也夹杂了其他标签。*和+都是所谓的 "贪婪型"(greedy)元字符,其匹配行为是多多益善而不是适可而止。它们会尽可能地从一段文本的开头一直匹配到末尾,而不是碰到第一个匹配时就停止。
在不需要这种 "贪婪行为" 的时候该怎么办?答案是使用这些量词的 "懒惰型"(lazy)版本(之所以称之为 "懒惰型" 是因为其匹配尽可能少的字符,而非尽可能多地去匹配)。懒惰型量词的写法是在贪婪型量词后面加上一个 ?。
| 贪婪型量词 | 懒惰型量词 |
|---|---|
* | *? |
+ | +? |
{n,} | {n,}? |
修改上面例子的正则表达式:<[Bb]>.*?<\/[Bb]>

例子三:使用子表达式嵌套寻找正确的 IP 地址
分析:IP 地址里的每一组数字都不能大于 255,所以一个有效的 IP 地址中每组数字必须符合以下规则。
- 任意的 1 位或 2 位数字;
- 任意的以 1 开头的 3 位数字;
- 任意的以 2 开头、第二位数字在 0 到 4 之间的 3 位数字;
- 任意的以 25 开头、第三位数字在 0 到 5 之间的 3 位数字。
Pinging hog.forta.com [12.159.46.200] with 32 bytes of data:
正则表达式:(((25[0-5])|(2[0-4]\d)|(1\d{2})|(\d{1,2}))\.){3}(((25[0-5])|(2[0-4]\d)|(1\d{2})|(\d{1,2})))
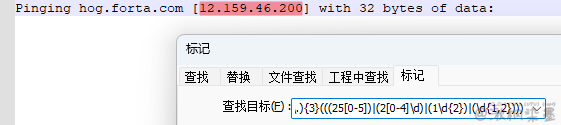
值得注意的是,上面表达式是按照分析过程逆着来写的。如果按照更符合逻辑的顺序书写,反倒是不行的。
把上面正则表达式按照分析顺序来写,修改为:(((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))\.){3}((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))
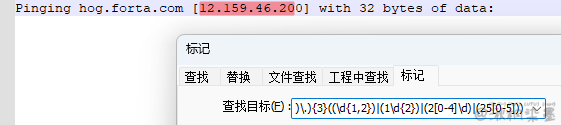
可以发现,最后IP地址结尾的数字 200 只匹配出 20
为什么会这样?因为模式是从左到右进行评估的,所以当括号内有 4 个表达式都可以匹配时,首先测试第一个,然后测试第二个,以此类推。只要有任何模式匹配,就不再测试选择结构中的其他模式。在本例中,(\d{1,2}) 匹配结尾的 200 中的 20,因此其他模式(包括最后那个需要的(25[0-5]))甚至都没有进行评估。
# 1.3 空白字符
在进行正则表达式搜索的时候,经常会需要匹配文本中的非打印空白字符。比如说,制表符或换行符找出来。这时候可以借助下表中列出的特殊元字符。
| 说 明 | 正则表达式 |
|---|---|
[\b] | 回退(并删除)一个字符(Backspace 键) |
\f | 换页符 |
\n | 换行符 |
\r | 回车符 |
\t | 制表符(Tab 键) |
\v | 垂直制表符 |
例子
"101","Ben","Forta"
"102","Jim","James"
"103","Roberta","Robertson"
"104","Bob","Bobson"
2
3
4
5
正则表达式:\r\n\r\n - 匹配两个连续的行尾标记

\r\n 匹配一个 "回车(carriage return) + 换行(line feed)" 组合。
Windows 使用这种组合作为结束标记。
Unix/Linux/Mac OSX 只使用 \n 即可。
为了通用不同平台,上面的表达式可以优化为 [\r]?\n[\r]?\n
上面这个例子里的正则表达式使用的是 [\r]? 而不是 \r?,在功能上二者完全等价。[ ] 的常规用法是把多个字符定义为一个集合,但有不少程序员喜欢把一个字符也定义为一个集合。这么做的好处是可以增加可读性和避免产生误解,让人们一眼就可以看出随后的元字符应用于谁。
# 1.4 特定字符
| 元字符 | 说 明 |
|---|---|
\d | 任何一个数字字符(等价于[0-9]) |
\D | 任何一个非数字字符(等价于[^0-9]) |
\w | 任何一个字母数字字符(大小写均可)或下划线字符(等价于[a-zA-Z0-9_]) |
\W | 任何一个非字母数字或非下划线字符(等价于[^a-zA-Z0-9_]) |
\s | 任何一个空白字符(等价于[\f\n\r\t\v]) |
\S | 任何一个非空白字符(等价于[^\f\n\r\t\v]) |
例子一:
var myArray = new Array();
...
if (myArray[0] == 0 ) {
...
if (myArray[10] == 10 ) {...}
}
2
3
4
5
6
正则表达式:myArray\[\d\]

上面正则表达式只能匹配单个数字,匹配不了 myArray[10]
例子二:
11213
A1C2E3
480755
48237
M1B4F2
90046555
H1H2H2
2
3
4
5
6
7
正则表达式:\w\d\w\d\w\d - 简略 (\w\d){3}

例子三:
Send personal email to ben@forta.com or ben.forta@forta.com. For questions about a book use support@forta.com. If your message is urgent try ben@urgent.forta.com. Feel free to send unsolicited email to spam@forta.com (wouldn't it be nice if it were that simple, huh?).
正则表达式:[\w.]+@[\w.]+\.\w+

当在字符集合里使用的时候,像 . 和 + 这样的元字符将被解释为普通字符,不需要转义。[\w.] 的使用效果与 [\w.] 是一样的。
例子四:
Hello .ben@forta.com is my email address.
正则表达式:\w+[\w.]*@[\w.]+\.\w+

# 1.5 POSIX 字符类
POSIX 是一种特殊的标准字符类集,也是许多正则表达式实现都支持的一种简写形式。
| 字符类 | 说 明 |
|---|---|
[:alnum:] | 任何一个字母或数字(等价于[a-zA-Z0-9]) |
[:alpha:] | 任何一个字母(等价于[a-zA-Z]) |
[:blank:] | 空格或制表符(等价于[\t ]) |
[:cntrl:] | ASCII 控制字符(ASCII 0 到 31,再加上 ASCII 127) |
[:digit:] | 任何一个数字(等价于[0-9]) |
[:graph:] | 和[:print:]一样,但不包括空格 |
[:lower:] | 任何一个小写字母(等价于[a-z]) |
[:print:] | 任何一个可打印字符 |
[:punct:] | 既不属于[:alnum:],也不属于[:cntrl:]的任何一个字符 |
[:space:] | 任何一个空白字符,包括空格(等价于[\f\n\r\t\v ]) |
[:upper:] | 任何一个大写字母(等价于[A-Z]) |
[:xdigit:] | 任何一个十六进制数字(等价于[a-fA-F0-9]) |
例子
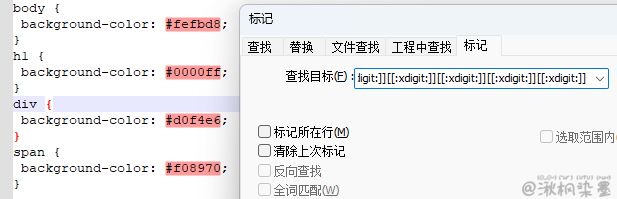
body {
background-color: #fefbd8;
}
h1 {
background-color: #0000ff;
}
div {
background-color: #d0f4e6;
}
span {
background-color: #f08970;
}
2
3
4
5
6
7
8
9
10
11
12
正则表达式:#[[:xdigit:]][[:xdigit:]][[:xdigit:]][[:xdigit:]][[:xdigit:]][[:xdigit:]] - 简略 #[[:xdigit:]]{6}
# 1.6 位置匹配
| 字 符 | 说 明 |
|---|---|
\b | 单词边界 |
^ | 字符串(文本)开头 |
$ | 字符串(文本)结尾 |
多行模式
^ 和 $ 通常分别匹配字符串的首尾位置。但也有例外,或者说有办法改变这种行为。
许多正则表达式都支持使用一些特殊的元字符去改变另外一些元字符的行为,
(?m)就是其中之一,它可用于启用多行模式(multiline mode)。多行模式迫使正则表达式引擎将换行符视为字符串分隔符,这样一来,^ 既可以匹配字符串开头,也可以匹配换行符之后的起始位置(新行);$ 不仅能匹配字符串结尾,还能匹配换行符之后的结束位置。在使用时,(?m) 必须出现在整个模式的最前面。最后需要说明,并非所有正则解析引擎都支持
例子一:
The cat scattered his food all over the room.
正则表达式:\bcat\b
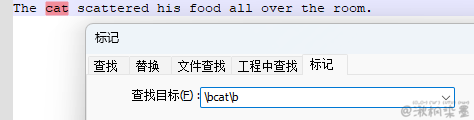
\b到底匹配什么东西呢?简单地说,匹配的是字符之间的一个位置:一边是单词(能够被 \w 匹配的字母数字字符和下划线),另一边是其他内容(能够被\W 匹配的字符)
例子二:检查是否xml文件格式开头,考虑空格
<?xml version="1.0" encoding="UTF-8" ?>
<wsdl:definitions targetNamespace="http://tips.cf"
xmlns:impl="http://tips.cf" xmlns:intf="http://tips.cf"
xmlns:apachesoap="http://xml.apache.org/xml-soap"
2
3
4
正则表达式:^\s*<\?xml.*\?>

例子三:检查web页面结尾</html>标签后面无任何内容
<html>
... ...
</html>
2
3
正则表达式:</[Hh][Tt][Mm][Ll]>\s*$

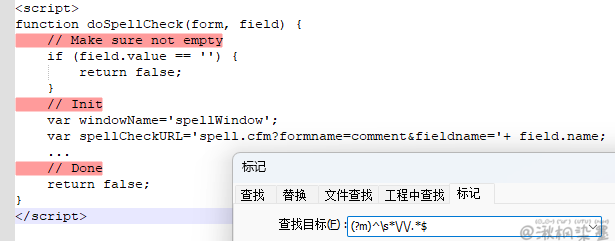
例子四:使用多行模式找出所有注释
<script>
function doSpellCheck(form, field) {
// Make sure not empty
if (field.value == '') {
return false;
}
// Init
var windowName='spellWindow';
var spellCheckURL='spell.cfm?formname=comment&fieldname='+ field.name;
...
// Done
return false;
}
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
正则表达式:(?m)^\s*\/\/.*$
# 二:反向引用
反向引用:指的是这些实体引用的是先前的子表达式。
要想理解为什么需要反向引用,最好的方法是看一个例子。找出下面HTML使用标题标签(<h1>到<h6>,以及配对的结束标签)及标题文字。
<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
<h2>This is not valid HTML</h3>
</body>
2
3
4
5
6
7
8
9
正则表达式:<[hH][1-6]>.*?<\/[hH][1-6]> - 这里使用 .*?(懒惰型)
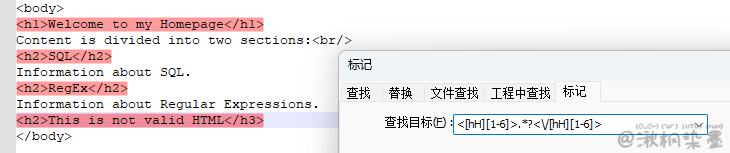
最后一条标题的标签是以 <h2> 开头、以 </h3> 结束的,这显然是一个无效的标题,但也能匹配上。问题在于匹配的第二部分(用来匹配结束标签的那部分)对匹配的第一部分(用来匹配开始标签的那部分)一无所知。这正是反向引用大显身手的地方了。
# 2.1 反向引用匹配
假设有一段文本,想把这段文本里所有连续重复出现的单词找出来。显然,在搜索某个单词的第二次出现时,这个单词必须是已知的。反向引用允许正则表达式模式引用之前匹配的结果。例如下面这个例子:
This is a block of of text, several words here are are repeated, and and they should not be.
正则表达式:[ ]+(\w+)[ ]+\1

上面正则表达式解析:
[ ]+匹配一个或多个空格,\w+匹配一个或多个字母数字字符,[ ]+匹配结尾的空格;\w+是出现在括号里的,所以它是一个子表达式。该子表达式并不是用来进行重复匹配的。它只是对模式分组,将其标识出来以备后用;- 最后一部分
\1,这是对前面那个子表达式的反向引用,\1 匹配的内容与第一个分组匹配的内容一样。因此,如果(\w+)匹配的是单词 of,那么 \1 也匹配单词 of。
回到刚刚HTML的例子,可以构造一个模式去匹配任何一级标题的开始标签以及相应的结束 标签(忽略任何不配对的标签)。
正则表达式:<[hH]([1-6])>.*?<\/[hH]\1>
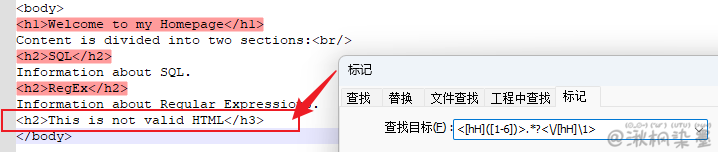
反向引用只能用来引用括号里的子表达式。
反向引用匹配通常从 1 开始计数(\1、\2 等)。在许多实现里,第 0 个匹配(\0)可以用来代表整个正则表达式。
\1在某些解析引擎解析不了,例如:需要替换$1等等。
# 2.2 替换操作
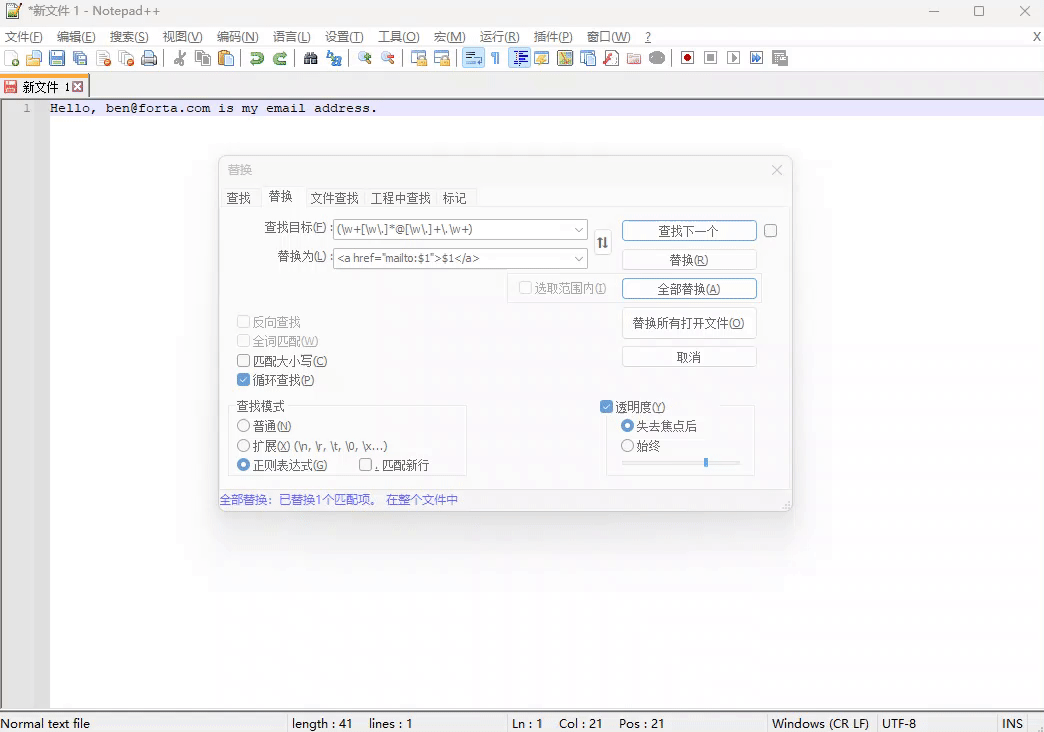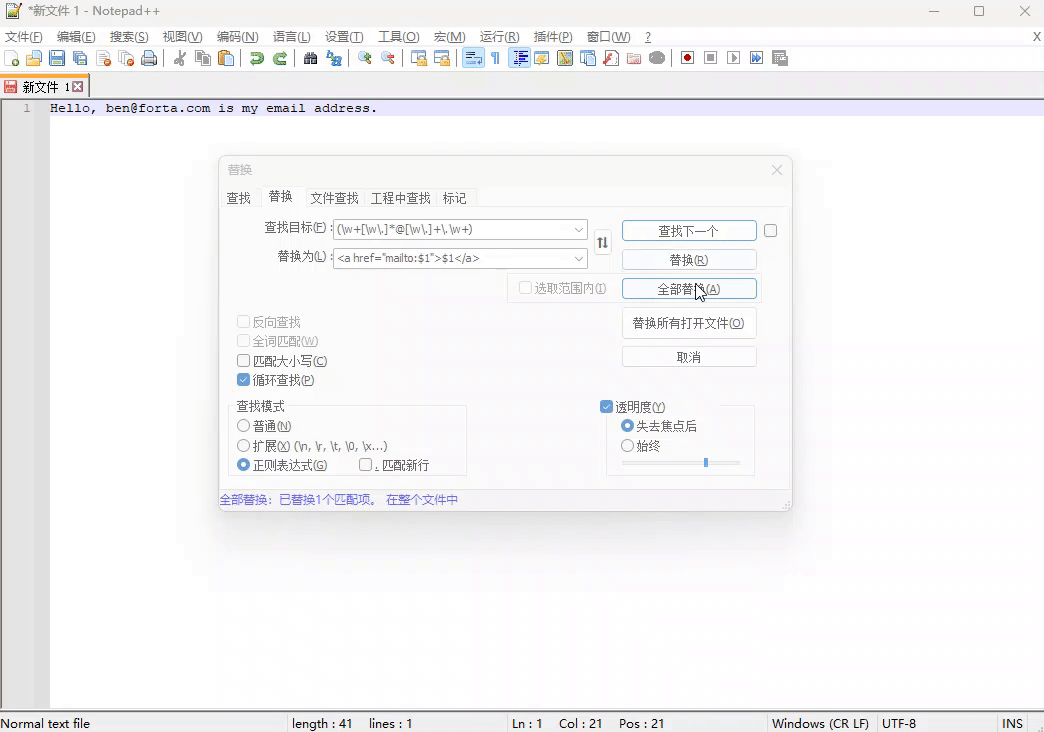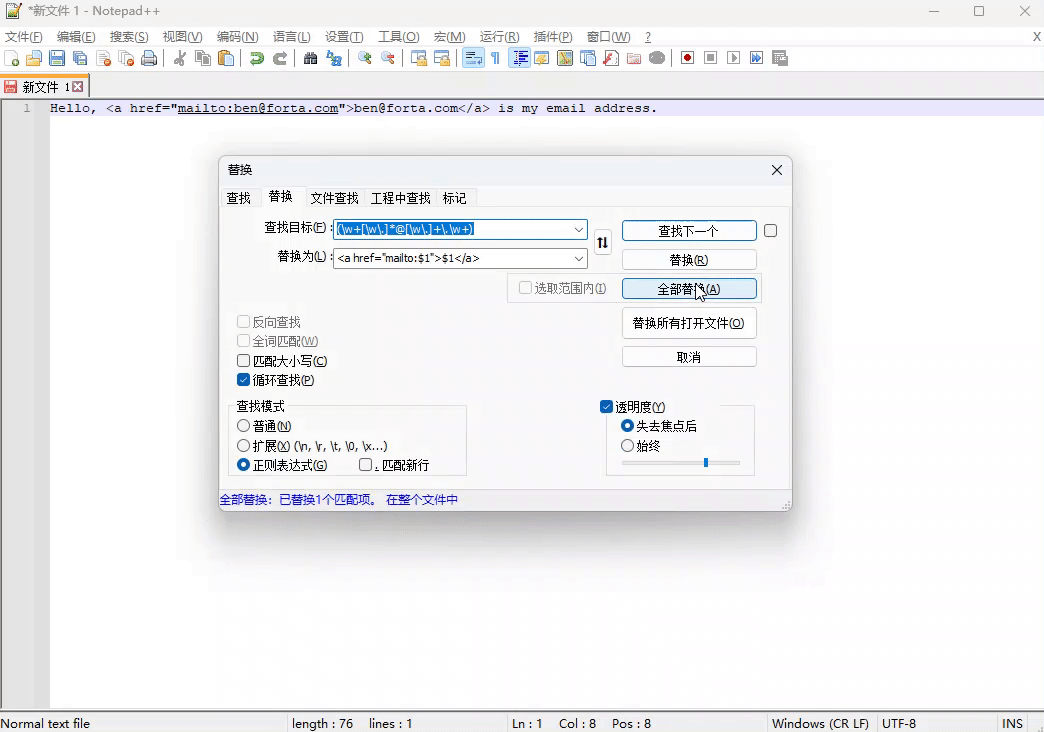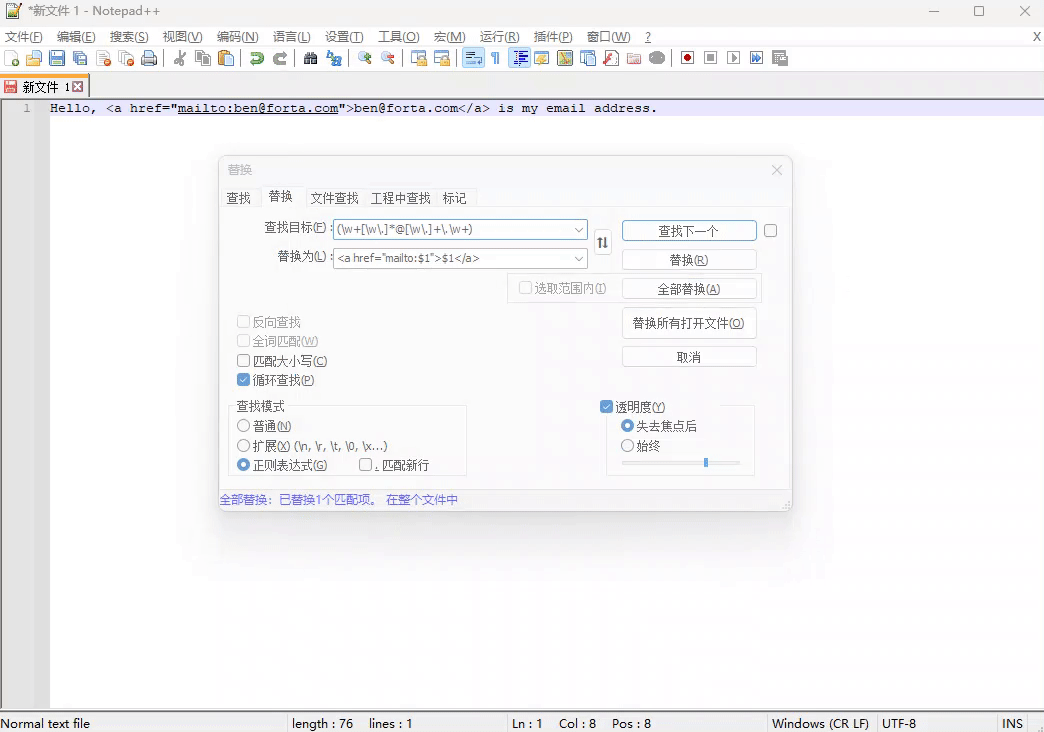
例子一:将下面的邮箱,替换成包含 HTML 的 <a> 标签
Hello, ben@forta.com is my email address.
正则表达式:(\w+[\w\.]*@[\w\.]+\.\w+) - 用来匹配邮箱
替换表达式: <a href="mailto:$1">$1</a>
上面使用的是 Notepad++ 软件,替换表达式中的 $1 可以修改为 \1,二者兼容。查找不兼容
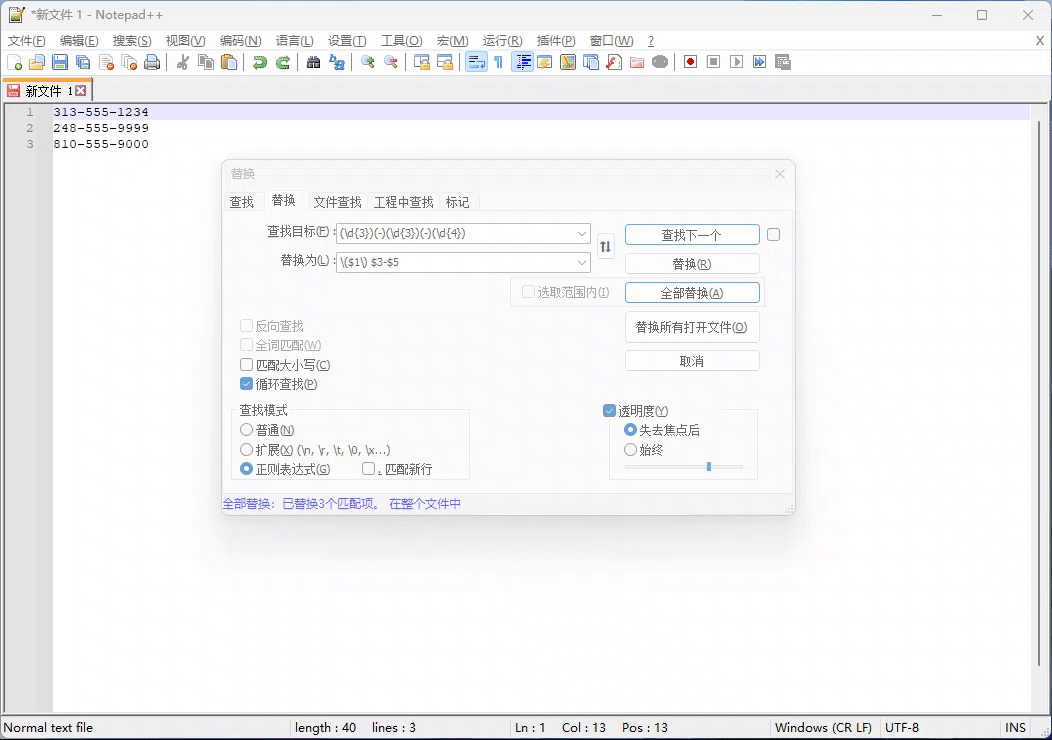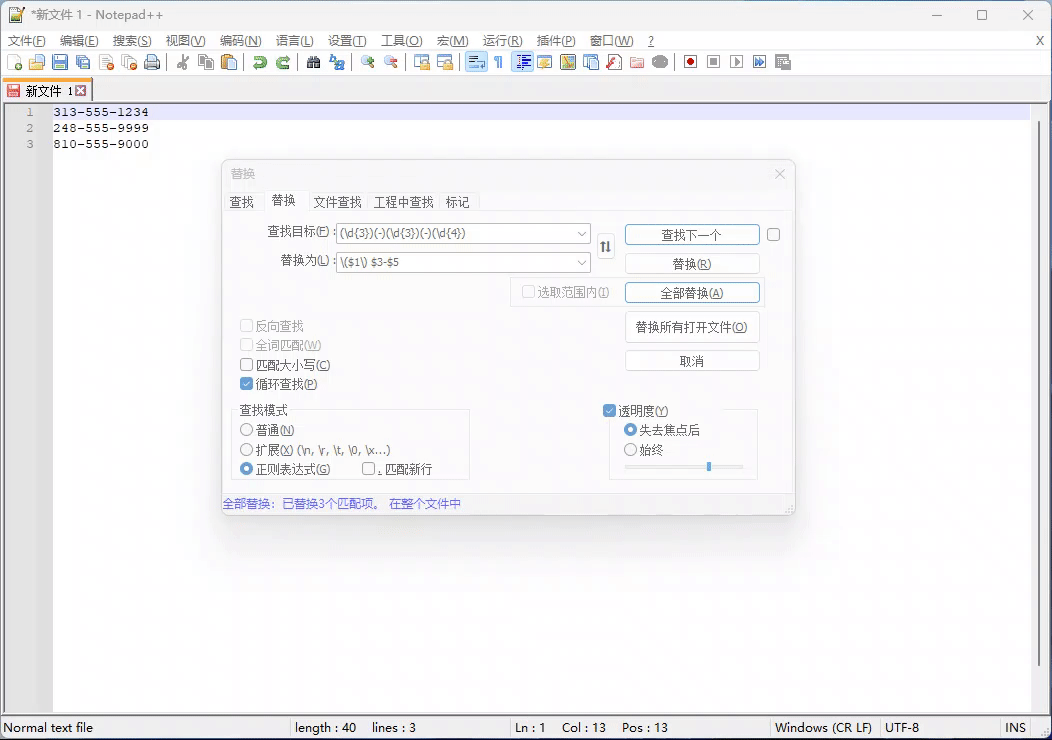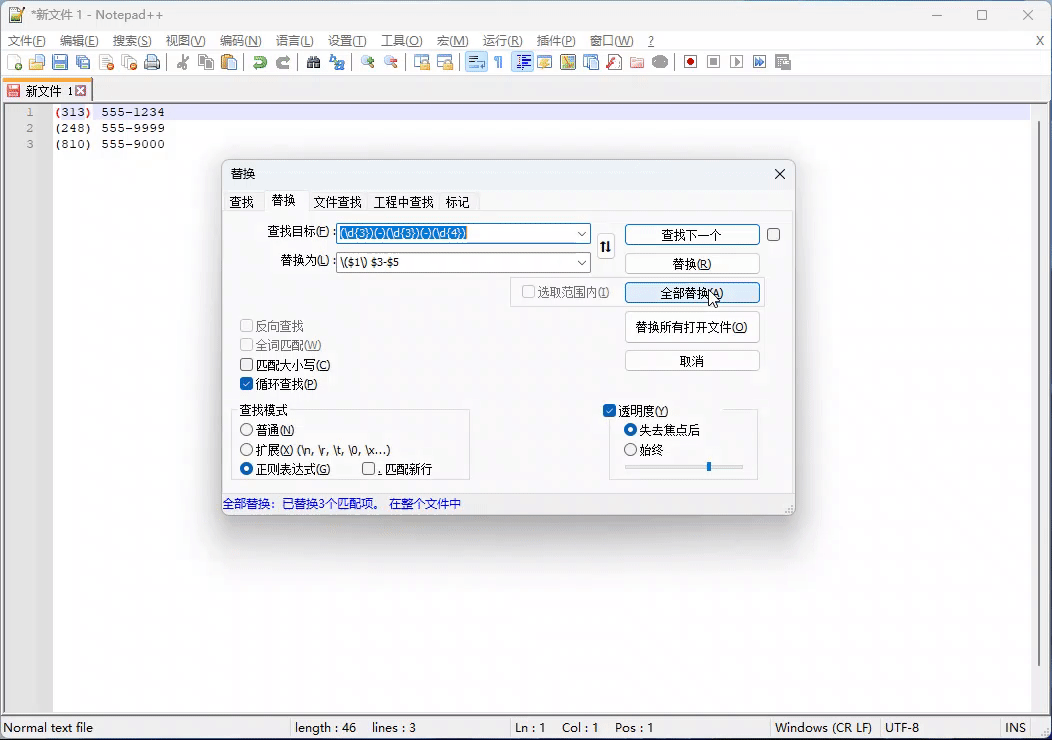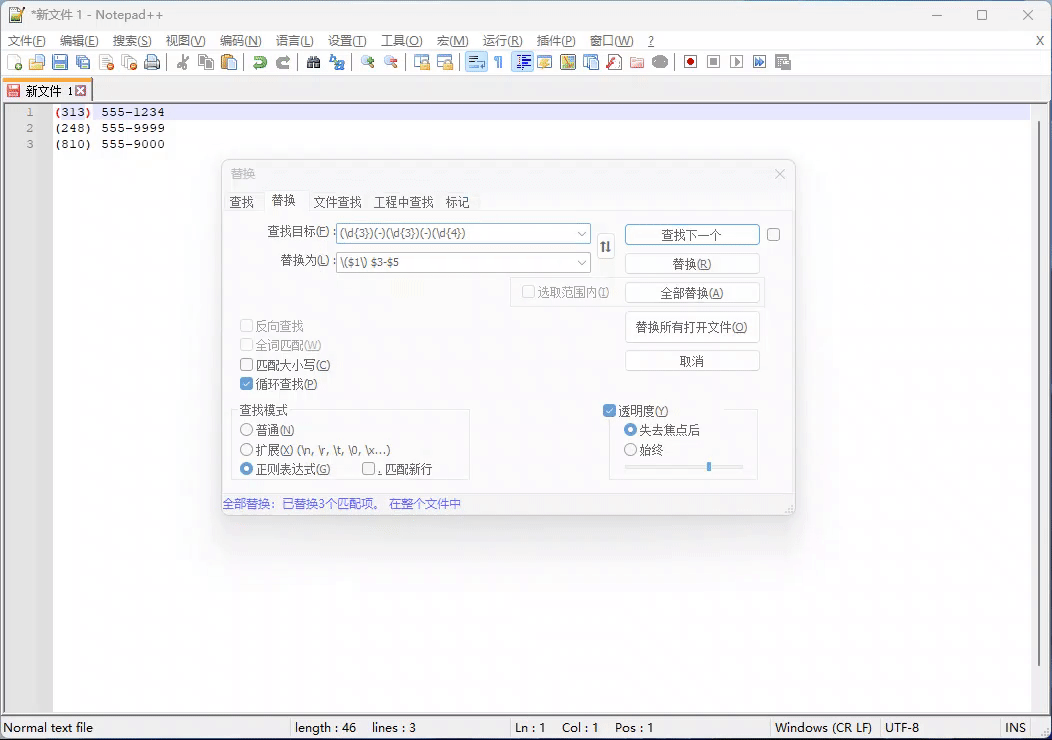
例子二:将下面的数字替换成 (313) 555-1234 带括号格式
313-555-1234
248-555-9999
810-555-9000
2
3
正则表达式:(\d{3})(-)(\d{3})(-)(\d{4})
替换表达式: ($1) $3-$5 - 部分解析器需要改成 \($1\) $3-$5 才生效
# 2.3 大小写转换
| 元字符 | 说 明 |
|---|---|
\E | 结束 \L 或 \U 转换 |
\l | 把下一个字符转换为小写 |
\L | 把 \L 到 \E 之间的字符全部转换为小写 |
\u | 把下一个字符转换为大写 |
\U | 把 \U 到 \E 之间的字符全部转换为大写 |
\l和\u可以放置在字符(或子表达式)之前,转换下一个字符的大小写;\L和\U可以转换其与\E之间所有字符的大小写。
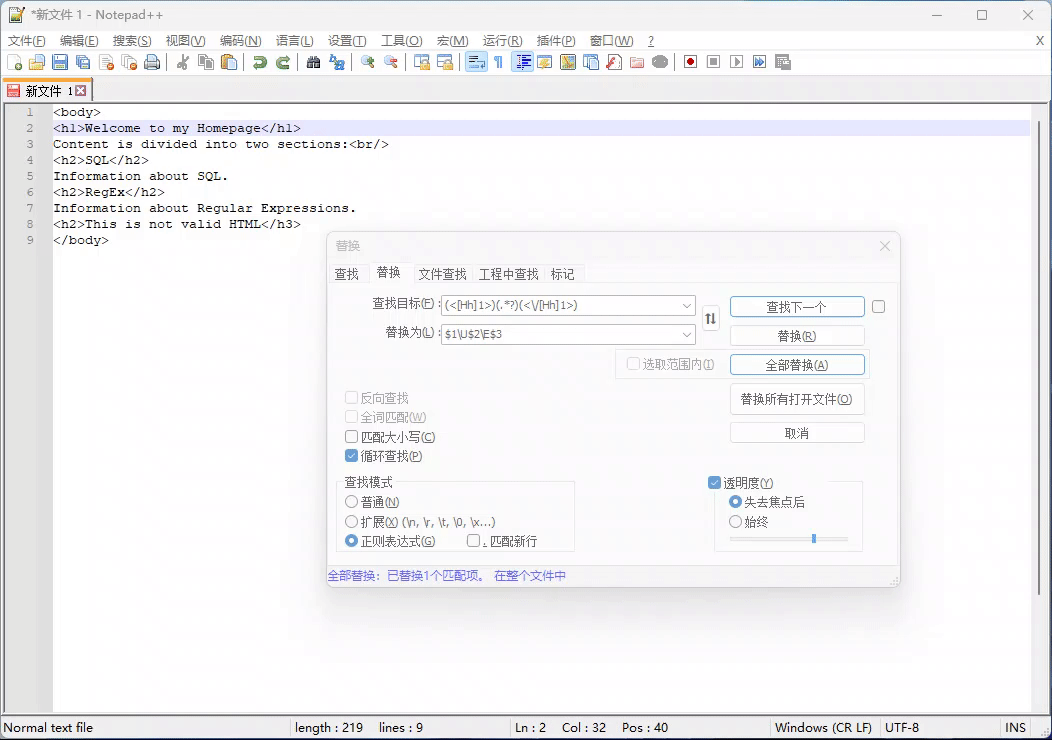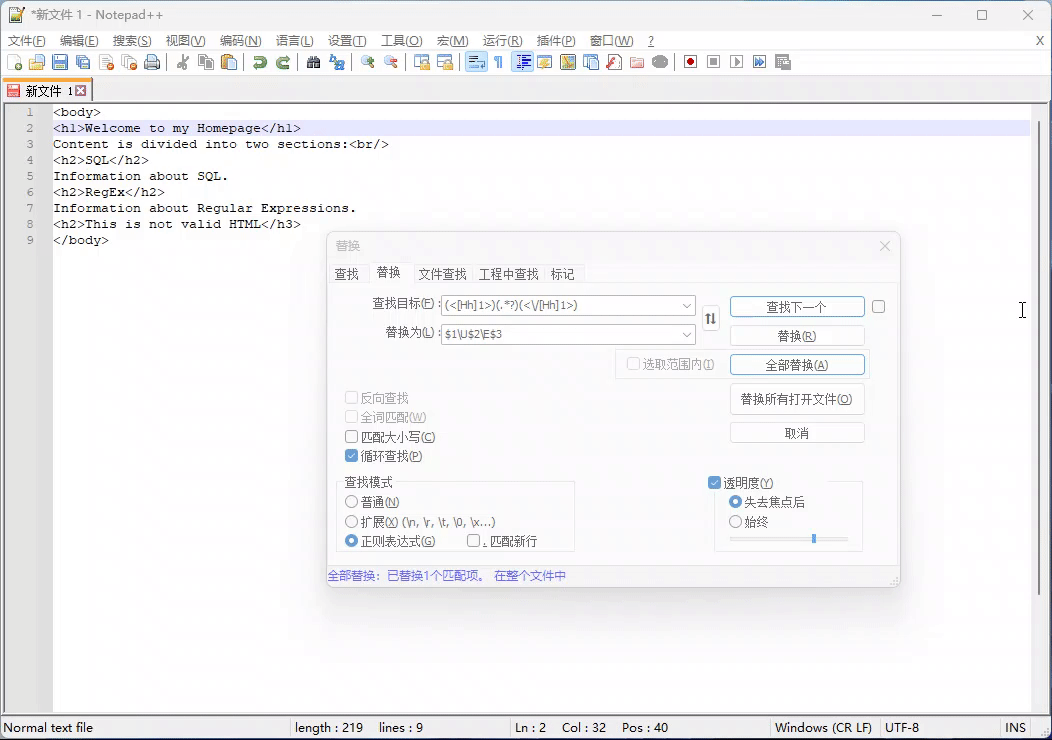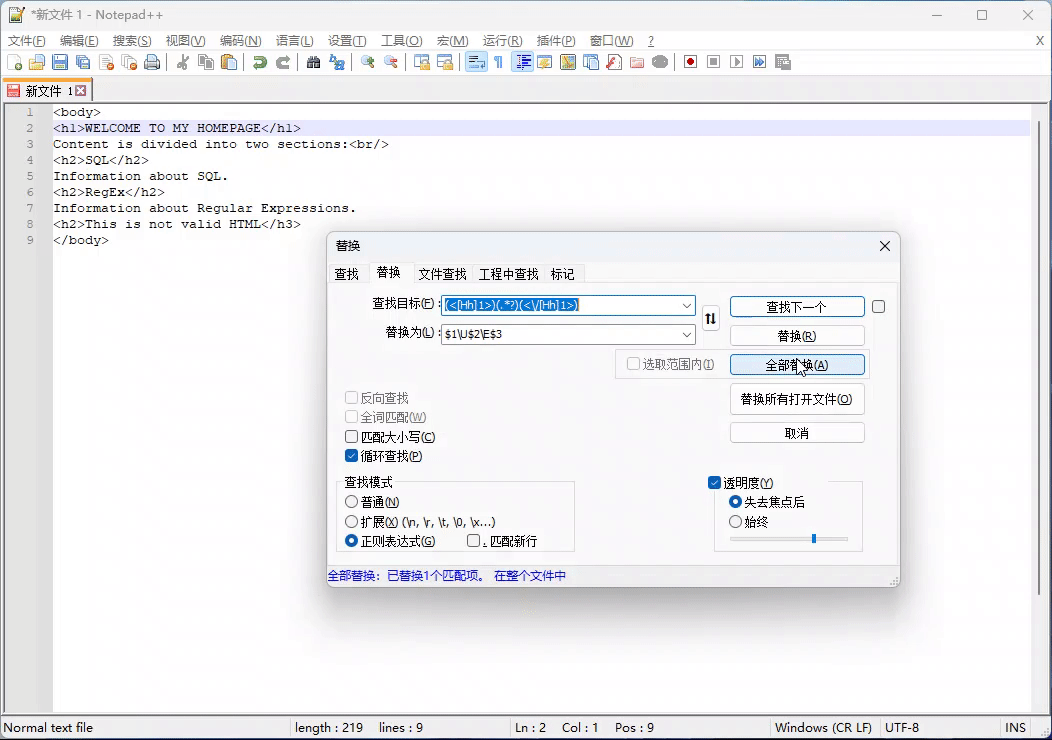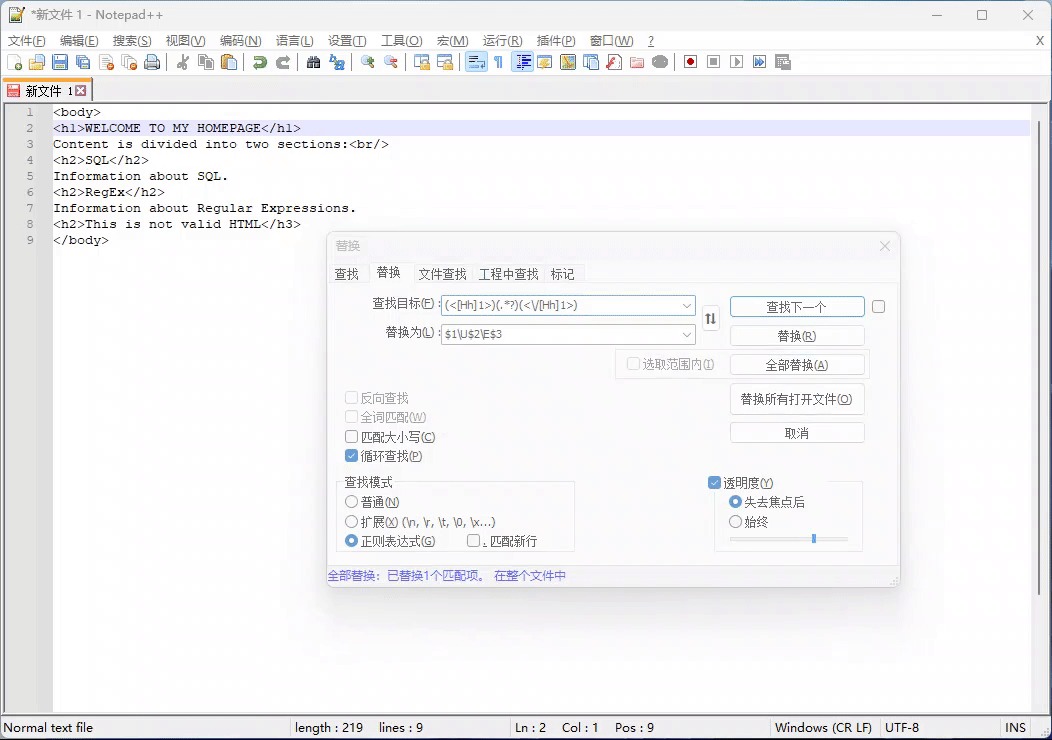
例子:把一级标题 <h1> 内容转换为大写:
<body>
<h1>Welcome to my Homepage</h1>
Content is divided into two sections:<br/>
<h2>SQL</h2>
Information about SQL.
<h2>RegEx</h2>
Information about Regular Expressions.
<h2>This is not valid HTML</h3>
</body>
2
3
4
5
6
7
8
9
正则表达式:(<[Hh]1>)(.*?)(<\/[Hh]1>)
替换表达式: $1\U$2\E$3
# 三:环视
如果想用正则表达式标记要匹配的核心文本内容(而不是文本自身)。这就要用到环视(lookaround,能够前后查看)了。
例子:取出 <title> 和 </title>标签之间的文字。
<head>
<title>Ben Forta's Homepage</title>
</head>
2
3
正则表达式:<[tT][iI][tT][lL][eE]>.*<\/[tT][iI][tT][lL][eE]>

使用上面的正则表达式就会发现,title 标签也包含进去,没法只提取标签之间的文字,这时候就需要 "环视"
向前查看(lookahead)和向后查看(lookbehind)所有主流的正则表达式实现都支持前者,但支持后者的就没那么多了。Java 支持
# 3.1 向前查看
向前查看指定了一个必须匹配但不用在结果中返回的模式。以 ?= 开头的子表达式,需要匹配的文本跟在 = 后面。
例子:提取每个地址的协议部分
http://www.forta.com/
https://mail.forta.com/
ftp://ftp.forta.com/
2
3
正则表达式:.+(?=:)

可以发现使用了环视之后,: 并没有出现在结果中。
# 3.2 向后查看
查看出现在已匹配文本之前的内容,向后查看操作符是 ?<=
例子:提取价格
ABC01: $23.45
HGG42: $5.31
CFMX1: $899.00
XTC99: $69.96
Total items found: 4
2
3
4
5
正则表达式:(?<=\$)[0-9.]+

回到开始的例子,取出 <title> 和 </title> 标签之间的文字。这时候需要结合向前查看和向后查看。
正则表达式:(?<=<[tT][iI][tT][lL][eE]>).*(?=</[tT][iI][tT][lL][eE]>)

为减少歧义,在上面这个例子里,应该对 <(需要匹配的第一个字符)进行转义,也就是把 (?<=< 替换为 (?<=\<
# 3.3 否定式环视
环视还有一种不太常见的形式叫作 否定式环视(negative lookaround)。否定式向前查看(negative lookahead) 会向前查看不匹配指定模式的文本,否定式向后查看(negative lookbehind) 则向后查看不匹配指定模式的文本。
| 种 类 | 说 明 |
|---|---|
(?=) | 肯定式向前查看 |
(?!) | 否定式向前查看 |
(?<=) | 肯定式向后查看 |
(?<!) | 否定式向后查看 |
例子:提取数量,不要价格
I paid $30 for 100 apples,
50 oranges, and 60 pears.
I saved $5 on this order.
2
3
正则表达式:\b(?<!\$)\d+\b

# 四:嵌入式条件
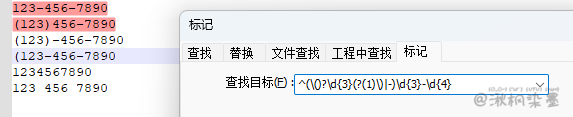
例子:提取 (123)456-7890 和 123-456-7890 格式的数据
123-456-7890
(123)456-7890
(123)-456-7890
(123-456-7890
1234567890
123 456 7890
2
3
4
5
6
正则表达式:\(?\d{3}\)?-?\d{3}-\d{4}

匹配到了第 3 行和第 4 行,这就不正确了(第 3 行的 ) 后面多了一个 -,第 4 行少了一个配对的 )。把 \)?-? 替换为 [\)-]? 可以排除第 3 行(只允许出现 )或-,两者不
能同时存在,但第 4 行还是无法排除。更准确地说,如果电话号码里有一个 (,模式就需要去匹配 );如果不是这样,那就得去匹配 -。这种模式如果不使用条件处理根本无法编写。
并非所有的正则表达式实现都支持条件处理
嵌入式条件不外乎以下两种情况:根据反向引用来进行条件处理 和 根据环视来进行条件处理。嵌入式条件语法使用 ?
# 4.1 反向引用条件
反向引用条件仅在一个前面的子表达式得以匹配的情况下才允许使用另一个表达式。有两种语法:
- if为true语法,用来定义这种条件的语法是
(?(backreference)true),其中?表明这是一个条件,括号里的 backreference 是一个反向引用,仅当反向引用立即出现时,才对表达式求值。 - else语法,仅当给定的反向引用不存在(也就是不符合条件)时才执行该表达式。用来定义这种条件的语法是
(?(backreference)true|false)。此语法接受一个条件和两个分别在 符合/不符合 该条件时执行的表达式。
例子:找出 <img> 标签,如果处于 <a> 标签中,匹配整个链接标签
<!-- Nav bar -->
<div>
<a href="/home"><img src="/images/home.gif"></a>
<img src="/images/spacer.gif">
<a href="/search"><img src="/images/search.gif"></a>
<img src="/images/spacer.gif">
<a href="/help"><img src="/images/help.gif"></a>
</div>
2
3
4
5
6
7
8
正则表达式:(<[Aa]\s+[^>]+>\s*)?<[Ii][Mm][Gg]\s+[^>]+>(?(1)\s*<\/[Aa]>)

正则表达式解析:
(<[Aa]\s+[^>]+>\s*)?匹配一个 <A> 或 <a> 标签(以及可能存在的任意属性),这个标签可有可无(因为这个子表达式的最后有一个?);<[Ii][Mm][Gg]\s+[^>]+>匹配一个 <img> 标签(大小写均可)及其任意属性;(?(1)\s*<\/[Aa]>)的起始部分是一个条件:?(1)表示仅当第一个反向引用(<A> 标签)存在,才继续匹配\s*<\/[Aa]>(换句话说,只有当第一个 <A> 标签匹配成功,才去执行后面的匹配)。如果(1)存在,\s*<\/[Aa]>匹配结束标签 </A> 之后出现的任意空白字符。
回到开始的例子,提取 (123)456-7890 和 123-456-7890 格式的数据。
正则表达式:^(\()?\d{3}(?(1)\)|-)\d{3}-\d{4}
# 4.2 环视条件
环视条件允许根据向前查看或向后查看操作是否成功来决定要不要执行表达式。环视条件的语法与反向引用条件的语法大同小异,只需把反向引用(括号里的反向引用编号)替换为一个完整的环视表达式就行了。
例子:提取 12345 和 12345-6789 格式的数据。
11111
22222
33333-
44444-4444
2
3
4
正则表达式:\d{5}(?(?=-)-\d{4})

正则表达式解析:
\d{5}匹配前 5 位数字;(?(?=-)-\d{4})这个条件使用向前查看?=-来匹配(但不消耗)一个连字符,如果符合条件(连字符存在),那么-\d{4}将匹配该连字符和随后的 4 位数字。这样一来,33333- 就被排除在最终的匹配结果之外了。
# 五:Java
# 5.1 String
String类里提供了如下几个特殊的方法:
boolean matches(String regex):判断该字符串是否匹配指定的正则表达式;String replaceAll(String regex, String replacement):将该字符串中所有匹配 regex 的子串替换成 replacement;String replaceFirst(String regex, String replacement):将该字符串中第一个匹配 regex 的子串替换成 replacement;public String[] split(String regex):以 regex 作为分隔符,把该字符串分割成多个子串。
public class StringTest {
public static void main(String[] args) {
String text1 = "Hello, ccj@qq.com is my email address.";
String text2 = "ccj@qq.com";
System.out.println("是否匹配正则表达式:" + text1.matches("\\w+[\\w\\.]*@[\\w\\.]+\\.\\w+"));
System.out.println("是否匹配正则表达式:" + text2.matches("\\w+[\\w\\.]*@[\\w\\.]+\\.\\w+"));
System.out.println("替换邮箱:" + text1.replaceAll("\\w+[\\w\\.]*@[\\w\\.]+\\.\\w+", "qform@163.com"));
System.out.println("使用反向引用替换:" + text1.replaceAll("\\w+[\\w\\.]*@[\\w\\.]+\\.\\w+", "<a href=\"mailto:$0\">$0</a>"));
String[] split = text1.split("\\w+[\\w\\.]*@[\\w\\.]+\\.\\w+");
Arrays.stream(split).forEach(e -> System.out.println("分隔的内容:" + e));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
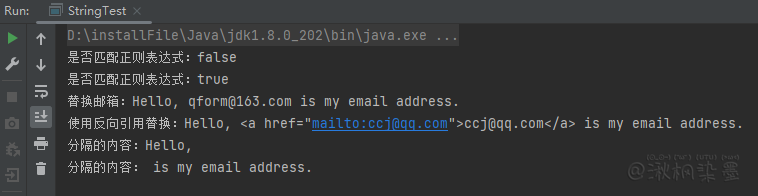
String 类的 matches 方法是 整个文本内容 是否符合入参的正则表达式。
# 5.2 Pattern 和 Matcher
Pattern对象是正则表达式编译后在内存中的表示形式,因此,正则表达式字符串必须先被编译为Pattern对象,然后再利用该Pattern对象创建对应的Matcher对象。执行匹配所涉及的状态保留在Matcher对象中,多个Matcher对象可共享同一个Pattern对象。Pattern是不可变类,可供多个并发线程安全使用。
典型的调用顺序如下:
// 将一个字符串编译成 Pattern 对象
Pattern p = Pattern.compile("a*b");
// 使用 Pattern 对象创建 Matcher 对象
Matcher m = p.matcher("aaaaab");
boolean b = m.matches(); // true
2
3
4
5
如果某个正则表达式仅需一次使用,则可直接使用 Pattern 类的静态 matches() 方法,此方法自动把指定字符串编译成匿名的 Pattern 对象,并执行匹配,如下所示。
boolean b = Pattern.matches("a*b", "aaaaab"); // true
上面语句等效于前面的三条语句。但采用这种语句每次都需要重新编译新的Pattern对象,不能重复利用已编译的Pattern对象,所以效率不高。
Matcher 类提供了如下几个常用方法。
boolean find():返回目标字符串中是否包含与Pattern匹配的子串;String group():返回上一次与Pattern匹配的子串;String group(int group):返回与Pattern匹配的指定位置子串;int start():返回上一次与Pattern匹配的子串在目标字符串中的开始位置;int end():返回上一次与Pattern匹配的子串在目标字符串中的结束位置加1;boolean lookingAt():返回目标字符串前面部分与Pattern是否匹配;boolean matches():返回整个目标字符串与Pattern是否匹配;Matcher reset(CharSequence input):将现有的Matcher对象应用于一个新的字符序列;String replaceFirst(String replacement):将该字符串中第一个匹配 regex 的子串替换成 replacement;String replaceAll(String replacement):将该字符串中所有匹配 regex 的子串替换成 replacement。
public class PatternTest {
public static void main(String[] args) {
test1();
System.out.println("=========================================");
test2();
}
private static void test1() {
String s = "Hello, ccj@qq.com is my email address.";
Matcher m1 = Pattern.compile("\\w+[\\w\\.]*@[\\w\\.]+\\.\\w+").matcher(s);
System.out.println("目标字符串:" + s);
System.out.println("是否匹配正则表达式:" + m1.matches());
System.out.println("是否匹配正则表达式:" + m1.lookingAt());
String text = "Java Hello World";
System.out.println("目标字符串:" + text);
Matcher m2 = Pattern.compile("\\w+").matcher(text);
System.out.println("是否匹配正则表达式:" + m2.matches());
System.out.println("是否匹配正则表达式:" + m2.lookingAt());
while (m2.find()) {
System.out.printf("%s字串的起始位置:%d,其结束位置:%d\n", m2.group(), m2.start(), m2.end());
}
}
private static void test2() {
String[] mails = {"aaaaa@163.com", "bbbbbbb@gmail.com", "dddddd@abc.xxx"};
String mailRegEx = "\\w{3,20}@\\w+\\.(com|org|cn|net|gov)";
Pattern mailPattern = Pattern.compile(mailRegEx);
Matcher matcher = null;
for (String mail : mails) {
// 首次运行 if 代码
if (matcher == null) {
matcher = mailPattern.matcher(mail);
} else {
matcher.reset(mail);
}
System.out.println(mail + (matcher.matches() ? "是" : "不是") + "一个有效的邮箱地址!");
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
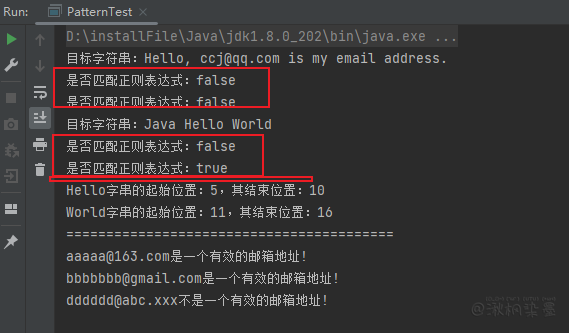
lookingAt() 方法会把检测到的内容消除。
matches() 和 lookingAt() 方法有点相似,只是 matches() 方法要求整个字符串和 Pattern 完全匹配时才返回 true,而 lookingAt() 只要字符串以 Pattern 开头就会返回true。reset() 方法可将现有的Matcher对象应用于新的字符序列。从某个角度来看,Matcher的 matches()、lookingAt() 和 String类的 equals()、startsWith() 有点相似。区别是 String 类的 equals() 和 startsWith() 都是与字符串进行比较,而 Matcher 的 matches() 和 lookingAt() 则是与正则表达式进行匹配。
# 六:参考文献
- 《正则表达式必知必会 - Ben Forta 著》